
1. 大模型持续学习的“失忆”困境
当我们惊叹于大语言模型(LLM)在翻译、编程、创意写作等任务上的出色表现时,一个隐藏的难题始终困扰着AI开发者:灾难性遗忘。简单来说,就是模型在学习新任务时,会“忘记”之前掌握的知识。例如,一个原本擅长中文翻译的模型,在经过法律文书生成任务微调后,可能突然无法准确翻译日常对话;一个能解数学题的模型,学习代码生成后,连基础算术题的正确率都大幅下降。
这种“学新忘旧”的现象,本质上是深度神经网络参数更新的“冲突”导致的。基础模型在预训练阶段积累了海量知识,但微调阶段为了适配新任务,参数会向新目标方向调整,若调整幅度过大,就会偏离原始知识分布,最终导致旧任务能力衰退。随着大模型在多场景落地,如何让AI像人类一样“温故知新”,成为持续学习领域的核心挑战。
2. 监督微调的局限
为了解决持续学习问题,传统方法中最常用的是监督微调(SFT)。这种方式通过在新任务数据集上直接最小化预测损失(如交叉熵损失)来更新模型参数,目标明确且易于实现。但正是这种“直接优化”的特性,成为了灾难性遗忘的诱因。
SFT的核心逻辑是“哪里错了改哪里”——通过梯度下降不断修正模型在新任务上的错误,直到损失函数最小化。但这会导致参数更新高度偏向新任务的数据分布,忽略对原始知识的保留。打个比方,SFT就像给模型“临时抱佛脚”,为了应付新考试(新任务)死记硬背考点,却忘了之前学过的基础知识。
实验数据显示,在典型的LLM微调场景中,SFT在新任务准确率达到90%以上时,旧任务的性能保留率往往不足60%(见表1)。这种“顾此失彼”的特性,让SFT难以满足多任务持续学习的需求。
3. RL的“保守更新”机制
2024年,AI研究者Arankomatsuzaki在其发布的“RL’s Razor”理论中提出了一个突破性观点:策略强化学习(On-policy RL) 天生具备缓解灾难性遗忘的能力,其核心在于参数更新的“保守性”——通过最小化KL散度(Kullback-Leibler divergence),让新模型分布尽可能贴近原始基础模型。
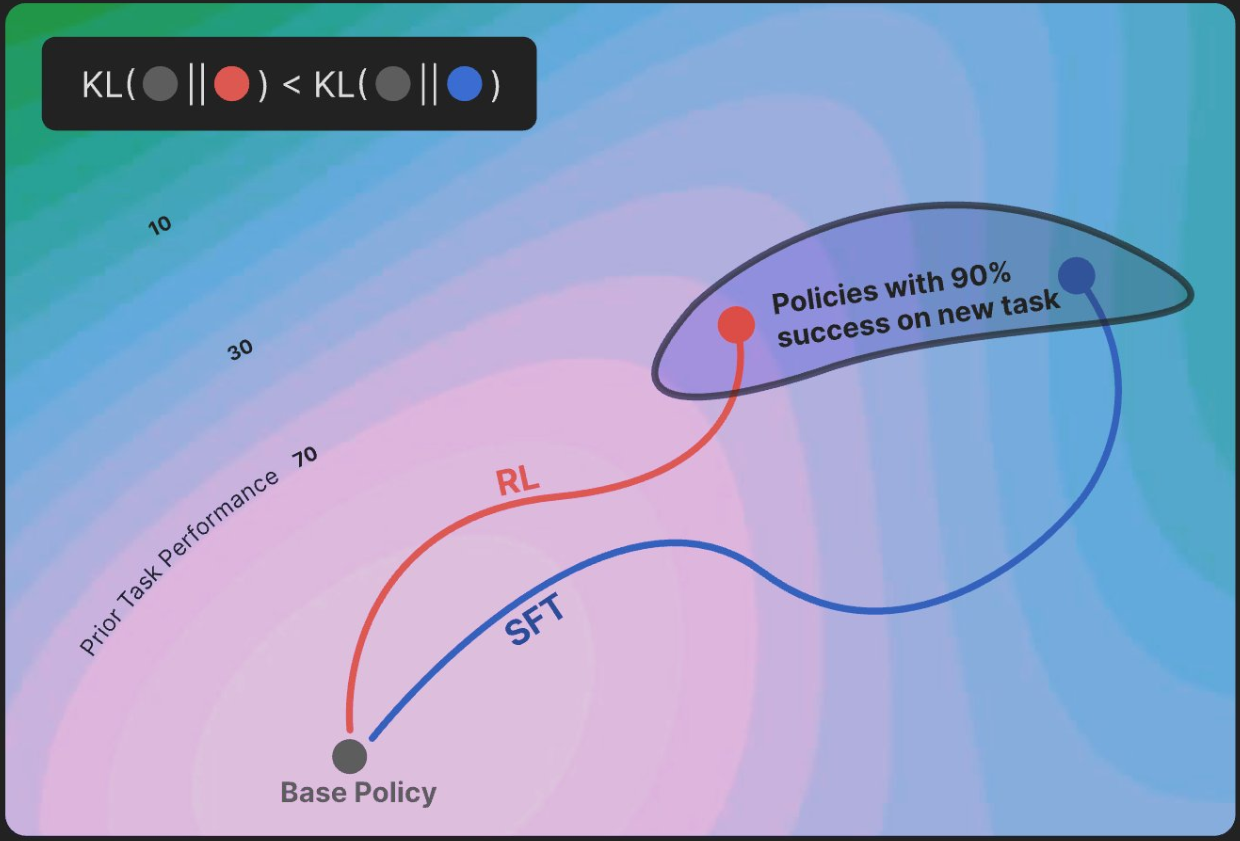
3.1 KL散度:衡量“分布差异”的数学工具
KL散度是信息论中的一个重要概念,用于度量两个概率分布之间的差异。如果将基础模型的知识分布比作“原始地图”,微调后的模型分布是“新地图”,KL散度就像两张地图的“重叠度评分”:KL值越小,说明新地图与原始地图重合度越高,模型对旧知识的保留就越好。
3.2 RL目标函数的“隐藏约束”
与SFT直接优化新任务损失不同,策略强化学习的目标函数中隐含了对KL散度的约束。
这意味着,RL在学习新任务时,会优先选择“离原始分布最近”的参数更新路径,就像给模型戴上“记忆枷锁”,防止它在学习新技能时“走得太远”。这种“保守更新”机制,正是RL缓解灾难性遗忘的关键。
4. 从理论到实践
“RL更能守护模型记忆”的结论并非空谈,多项实验从不同维度验证了这一机制的有效性。
4.1 旧任务保留率提升20%+
研究团队在主流大模型(如基于Llama-2的7B模型)上对比了SFT与RL的微调效果。实验选择GSM8K(数学推理)和HumanEval(代码生成)作为“旧任务”,以医疗问答数据集作为“新任务”,结果如下表所示:
| 微调方式 | 新任务准确率 | 旧任务保留率(数学+代码) | 灾难性遗忘程度 |
|---|---|---|---|
| SFT | 92.3% | 61.5% | 高 |
| On-policy RL | 92.4% | 81.7% | 低 |
表1:SFT与RL在大模型微调中的性能对比(数据来源:Arankomatsuzaki实验结果)
可以看到,RL在新任务准确率与SFT基本持平(92.4% vs 92.3%)的情况下,旧任务保留率提升了20.2个百分点,灾难性遗忘程度显著降低。
4.2 极简模型验证KL保守性
为排除复杂模型的干扰,研究团队构建了一个“玩具模型”——线性神经网络,仅包含10个参数,用于学习两个简单分类任务(任务A:区分圆形/方形;任务B:区分红色/蓝色)。实验发现:
- SFT微调任务B后,模型在任务A上的准确率从98%降至52%(接近随机猜测);
- RL微调后,任务A准确率仍保持在91%,参数变化幅度仅为SFT的1/3。
这一结果直观证明:RL的KL约束能有效限制参数偏离原始分布,即使在极简场景中依然生效。
5.RL如何重塑大模型微调流程
RL缓解灾难性遗忘的能力,已开始影响行业的模型优化策略。目前,多家科技公司已将RL思想融入微调方案:
- OpenAI/Claude:在ChatGPT、Claude的迭代中,RLHF(基于人类反馈的强化学习)不仅用于对齐人类偏好,还通过引入“KL惩罚项”(如PPO-KL算法)控制参数更新幅度,防止模型在迭代中丢失基础能力;
- Meta:提出“螺旋课程微调”框架,将SFT与RL交替进行——先用SFT快速学习新任务,再用RL“拉回”参数至原始分布附近,平衡学习效率与记忆保留;
- Google Gemini:结合MoE(混合专家模型)与RL,让不同专家模块负责不同任务,RL则用于优化专家间的“知识共享权重”,减少任务冲突导致的遗忘。
这些实践表明,RL已从理论走向落地,成为构建“持续进化型AI”的核心工具。
6. 挑战与未来
尽管RL展现出优势,但其在持续学习中的应用仍面临挑战:
- 多任务冲突困境:当新任务与旧任务知识高度冲突(如“纠正模型之前的错误认知”)时,KL约束可能阻碍模型更新,导致新任务性能下降;
- 训练不稳定性:RL训练的高方差问题可能导致参数更新“忽左忽右”,需要更精细的超参数调优;
- 计算成本:RL的在线更新(on-policy)需要实时生成样本,计算量是SFT的3-5倍,对边缘设备不友好。
未来,解决这些问题可能需要“组合策略”:例如,将RL与“记忆回放”(定期用旧任务数据微调)结合,或设计动态KL权重(任务冲突小时放松约束,冲突大时增强约束)。
大模型的“灾难性遗忘”本质上是AI“成长的烦恼”——如何在快速迭代中保留核心能力,是实现“通用人工智能”的必经之路。RL通过KL散度最小化机制,为这一难题提供了全新思路:好的学习不仅要“学得多”,更要“忘得少”。
随着RL与多任务学习、模型架构创新(如MoE)的深度融合,我们有理由期待:未来的AI系统能像人类一样,在学习新技能的同时,守护好积累的知识,真正实现“温故而知新”。
参考链接:
- Arankomatsuzaki推文:https://twitter.com/arankomatsuzaki/status/1963823603469730114
评论