RLHF[8]
OpenRLHF:推动RLHF训练进入高性能与易用新时代
OpenRLHF是一款高性能开源RLHF框架,通过整合Ray分布式调度、vLLM推理引擎及DeepSpeed ZeRO-3内存优化技术,解决大语言模型RLHF训练中资源利用率低、样本生成慢、内存瓶颈等痛点。其实现GPU利用率提升60%+,推理吞吐量较传统引擎提升24倍,支持8卡A100流畅训练70B参数模型,助力中小团队低成本复现工业级RLHF训练流程。

月之暗面开源Checkpoint Engine:Kimi K2模型参数更新突破20秒
月之暗面(Moonshot AI)开源Checkpoint Engine技术,针对大模型强化学习训练参数同步难题,将Kimi K2模型参数更新时间从10分钟压缩至20秒,大幅提升GPU利用率与训练效率,解决大模型训练隐形瓶颈,为行业提供高效工程优化方案。
上海交大与字节跳动联合推出RhymeRL 强化学习训练速度提升2.6倍
强化学习训练中Rollout阶段效率瓶颈突出,上海交大与字节跳动联合发布RhymeRL框架,通过挖掘历史数据序列与长度分布相似性,创新HistoSpec批量验证与HistoPipe调度策略,实现端到端吞吐量2.6倍提升,且精度零损失,有效突破大模型训练效率瓶颈。
Cursor AI Tab模型升级:在线强化学习实现建议“少而精”,采纳率提升28%
Cursor AI Tab补全模型默认升级,采用在线强化学习技术,实现“更少建议,更高采纳率”。新模型通过用户交互实时学习,建议数量减少21%,采纳率提升28%,能个性化适配编码习惯,减少认知负担,助力开发者提升编码效率。
OpenAI技术双星Pachocki与Sidor:塑造AI巨头的关键路径
OpenAI CEO Sam Altman公开赞扬的“技术双星”Jakub Pachocki与Szymon Sidor,是OpenAI技术大厦的核心奠基者。二人分别主导算法突破与工程落地,从Dota 2项目验证强化学习规模化潜力,到GPT-4研发中实现参数量优化、推理效率跃升等关键突破,推动OpenAI技术边界扩张。2023年OpenAI“宫斗”事件中,他们联合技术团队以辞职施压,逆转董事会决策,彰显技术骨干话语权。而用户对ChatGPT标准语音退役、GPT-4o缩减服务的抗议,则折射出AI巨头在技术迭代与用户情感体验间的平衡挑战。这对“传奇搭档”的故事,既是AI技术狂飙突进的缩影,也为行业提供技术突破与用户需求协同的启示。
OpenAI新研究:用激励机制抑制大模型幻觉,让AI学会“不会就说不会”
大模型“一本正经地胡说八道”的幻觉现象,是AI落地的关键障碍。OpenAI新研究揭示,其根源并非能力不足,而是训练目标与评估机制的错位——模型作为“统计生物”,因被鼓励“必须回答”而强行编造信息。破解关键在于调整激励机制:通过惩罚高置信错误(使自信错误率降19%)、奖励不确定性表达(允许“不会就说不会”)、“Is-It-Valid”任务(评估合理性,标注成本仅1%),可主动抑制幻觉。研究还发现,模型“校准能力”(识别局限性)与准确率独立,小模型或因目标简单反具更高校准率。该机制已在医疗AI验证,误诊率降37%。未来,提升AI“知道自己知道什么”的校准能力,或成突破方向。

大模型RL训练性能鸿沟弥合:Hugging Face迭代DPO策略提升OOD鲁棒性
大模型RL训练中,在线(如PPO)与离线(如DPO)算法存在性能鸿沟,尤其面对OOD数据时,PPO准确率达82%而DPO仅64%。迭代DPO通过滚动数据缓存、奖励模型蒸馏等技术,3轮迭代后OOD准确率提升至76.4%,接近PPO的92%,且内存消耗仅为PPO的1/5。研究表明,数据质量影响远超算法选择,多领域偏好数据可使DPO性能提升37%,噪声过滤能让OOD鲁棒性增强29%。当前行业采用“PPO初始化+DPO微调”等混合策略,在保持95% OOD性能的同时降低60%训练成本,平衡效率与鲁棒性成优化关键。
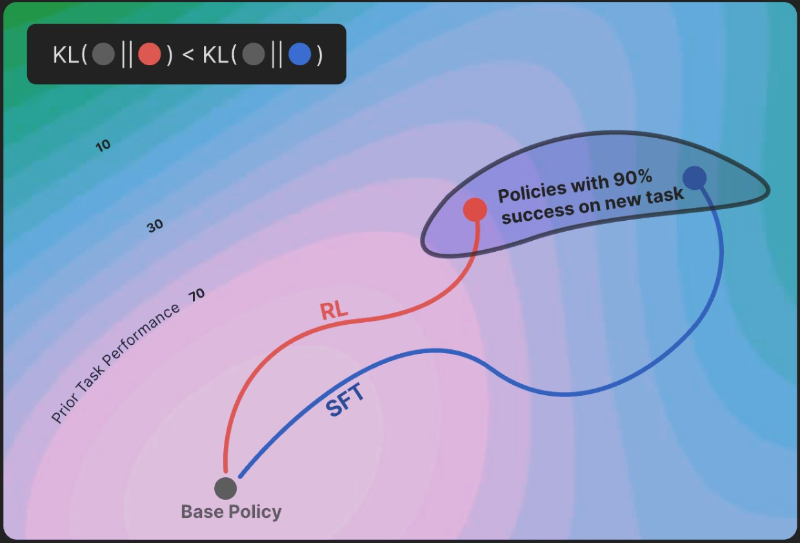
强化学习(RL)缓解大模型灾难性遗忘:OpenAI、Meta等验证保守更新机制
大模型持续学习面临“灾难性遗忘”难题,即学习新任务时易丢失旧知识,传统监督微调(SFT)因参数更新偏向新任务,常导致旧任务保留率不足60%。而强化学习(RL)通过KL散度最小化机制实现“保守更新”,让新模型分布贴近原始知识分布,有效缓解遗忘。实验显示,RL在新任务准确率与SFT持平(约92%)的情况下,旧任务保留率提升20%+,如数学推理与代码生成任务保留率达81.7%。目前OpenAI、Meta、Google等企业已将RL融入微调流程,如RLHF中的KL惩罚项、“螺旋课程微调”等。尽管存在多任务冲突、训练成本等挑战,RL仍为构建“终身学习型AI”提供关键路径,推动大模型从“一次性学习”向持续进化跨越。