评测基准[13]
ScaleAI推出SWE-Bench Pro 重塑AI长周期软件工程能力评估标准
2025年9月ScaleAI发布的SWE-Bench Pro,重新定义AI软件工程能力评估,从单文件修复升级至全流程开发任务,覆盖企业级代码库(平均20万行)、多模块协同及依赖处理。基于Docker+Modal框架构建可靠评测环境,支持分布式测试,微软、Waymo等企业应用后显著提升开发效率,推动AI从代码助手迈向工程伙伴。

全新基准SWE-rebench发布:标准化、透明化评估软件工程LLM
大型语言模型(LLM)正重塑软件工程,GitHub Copilot、ChatGPT等成开发者工具,但现有评估存数据污染、脚手架差异等痛点。全新基准SWE-rebench通过去污染数据集、统一ReAct框架、透明化流程等,解决评估不公问题,为LLM软件工程能力提供标准化衡量方案,推动行业从"指标优化"转向核心能力提升。
LiveMCP-101框架:开启AI智能体真实世界评估新阶段
AI智能体评估存在“模拟到现实鸿沟”,虚拟测试难测真实可靠性。微软与北大联合发布LiveMCP-101,系首个直接交互真实计算机系统的评估协议,含101项任务,覆盖系统操作、网络管理、安全响应等真实场景,解决传统虚拟测试局限,推动AI从实验室到真实世界的可靠落地。
上交大开源MobiAgent:全栈移动端AI Agent工具链
上海交大IPADS实验室开源MobiAgent移动端AI智能体工具链,含数据收集、训练、推理加速、自动评测四大模块,支持定制手机AI助手。7B参数模型性能超越GPT-5,AgentRR“肌肉记忆”技术提速2-3倍,端侧处理保障隐私,低功耗降30%-50%能耗,全流程工具链大幅降低开发门槛。
商汤「日日新V6.5」多模态大模型登顶OpenCompass全球榜单 超越Gemini 2.5 Pro与GPT-5
商汤「日日新V6.5」多模态大模型在OpenCompass评测中以82.2分超越Gemini 2.5 Pro与GPT-5,成全球领先。核心「图文交错思维链」技术贴近人类认知,优化视觉编码器与多模态网络,推理效率提升超三倍,标志中国AI在多模态通用智能领域迈入新阶段。
华为开源7B模型:快慢思考自适应 精度不减思维链缩短近50%
华为开源openPangu-Embedded-7B-v1.1大模型,创新“双重思维引擎”实现快慢思考自适应切换,采用渐进式微调训练。权威评测显示,通用任务(CMMLU)、数学难题(AIME)等精度提升超8%,思维链长度缩短近50%,效率精度双提升,同步推出1B边缘模型,开源推动行业创新。
蚂蚁集团AQ-MedAI提出DIVER框架:RAG技术从关键词匹配迈向逻辑链推理
传统RAG技术依赖关键词匹配,在医学诊断、数学证明等复杂任务中难以挖掘深度逻辑关联。为此,BRIGHT基准应运而生,聚焦推理密集型检索评价。蚂蚁集团提出DIVER框架,通过“预处理→查询扩展→推理检索→重排序”四阶段协同,将推理嵌入检索全流程,实现从关键词到逻辑链的跨越。该框架登顶BRIGHT基准,nDCG@10得分45.8,在医学、数学、编程等场景显著提升检索准确率,且泛化性强。目前论文、代码及模型已开源,助力AI从信息匹配迈向逻辑推理,赋能医疗辅助诊断、教育解题等领域发展。
SWE-bench团队发布多语言基准,开启LLM跨语言代码评估新时代
SWE-bench Multilingual是首个系统性评估大型语言模型(LLM)跨语言代码修复能力的权威基准测试,填补了LLM在多语言软件工程场景下的评估空白。该基准覆盖C、C++、Java、JavaScript、Rust等9种主流编程语言,包含300项真实任务,数据精选自42个高星GitHub仓库(如Next.js、Spring Boot、Tokio),经四重严格筛选确保测试完备、问题聚焦且可复现。通过双重验证机制(验证修复有效性与功能兼容性),实测显示LLM在Rust等强类型语言解决率最高,C/C++表现垫底,揭示语言特性对模型能力的显著影响。作为企业级多语言开发的重要评估工具,其开放数据集已助力LLM跨语言迁移研究与开发助手优化,为模型迭代与工程能力提升提供关键参考。
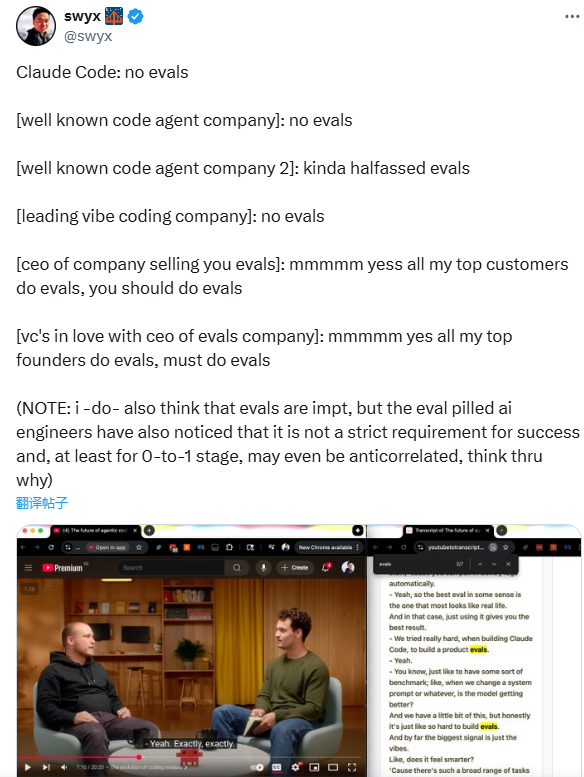
AI评估悖论:头部AI公司早期"不评估",行业热捧背后的阶段策略
AI行业存在“评估悖论”:顶尖AI公司在0-to-1阶段常不做僵化评估,而行业工具商与资本却力推评估为“必备技能”。头部企业“不评估”实为策略——早期依赖轻量试错与用户反馈,快速验证价值而非纠结性能指标;行业推崇评估则因工具商以评估为核心产品,资本需可衡量确定性降低风险。
评估价值取决于项目阶段:初创期过度评估易成“创新枷锁”,应优先用户反馈、轻量A/B测试;成熟扩展期则需系统化评估,优化性能、控制合规风险。真正的评估智慧在于:理解阶段需求,0-to-1阶段聚焦“用户是否需要”,成熟阶段用指标保障规模化落地,让评估服务创新而非束缚。
OpenAI解析AI幻觉:评估机制鼓励猜测,改革路径降低错误
AI幻觉是指AI生成自信却错误答案的现象,已成为AI信任危机主因。OpenAI研究显示,问题根源在于评估机制:当前以“准确率”为核心的规则,奖励“猜答案”、惩罚“承认无知”,导致模型偏爱“宁错勿空”。如SimpleQA测试中,早期模型为98.5%准确率付出12.7%幻觉率代价,优化评估后GPT-5幻觉率骤降至4.3%。此外,语言模型“预测下一个词”的训练逻辑,使其难辨“事实”与“模式”,低频事实易靠概率猜测。解决需重构评估(如惩罚自信错误、奖励弃权)、技术优化(置信度评分、验证链)及场景化动态调节。目前HaluEval 2.0等新基准推动行业变革,OpenAI已将“降低幻觉”纳入产品级建设,标志AI从“准确率崇拜”转向“可信协作”。