
1. AI行业的“评估悖论”
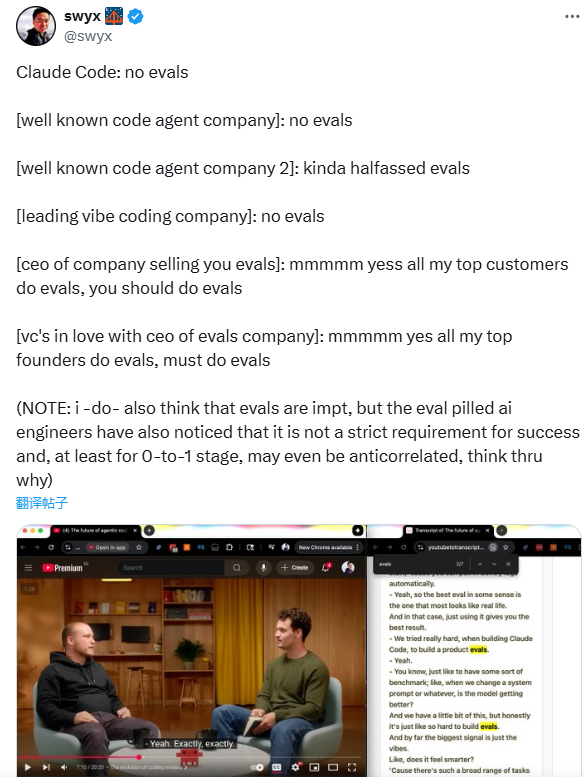
近期,知名技术KOL Swyx(Shawn Wang)在Twitter上抛出的一个观察引发了AI圈的热烈讨论:顶尖AI公司往往“不评估”,但整个行业却将“评估”(evals)奉为必备技能。这一矛盾现象,被他称为“AI评估悖论”——一边是Claude Code等头部代码代理公司在内部开发中“不做评估”或仅走形式,另一边却是评估工具厂商CEO和风险投资人在公开场合疾呼“评估决定项目成败”“所有优秀创始人都在做评估”。这种张力不仅揭示了AI开发实践与行业共识的割裂,更让从业者不得不重新思考:评估在AI创新中,究竟扮演什么角色?
2. 头部AI公司的“不评估”真相:是敷衍还是策略?
Swyx在推文中点名了多家头部AI企业的“不评估”实践:Claude Code完全不做评估,部分知名代码代理公司仅进行“不彻底”的形式化测试,甚至行业领先的“气氛公司”也几乎跳过评估环节。这些公司的市场成功(如用户增长、商业化落地)与“不评估”的操作形成了鲜明对比——难道评估真的不重要?
真相或许并非“完全不评估”,而是“不做僵化的系统性评估”。据行业博客Towards Data Science的后续调研,这些头部公司在早期开发中更依赖“轻量级试错”:快速推出MVP(最小可行产品),直接收集用户反馈,而非先通过复杂的指标测试(如Benchmark跑分、多维度性能评估)。例如,某匿名代码代理公司的产品经理透露:“我们早期甚至不设评估指标,只看用户是否愿意付费续约——这比任何测试数据都真实。”
这种“反直觉”的操作背后,是0-to-1阶段的核心需求:快速验证价值,而非优化性能。当产品还在探索“用户是否需要”时,过度纠结于“模型准确率提升0.5%”或“响应速度缩短100ms”,反而可能错过真正的用户痛点。
3. 行业为何力推“评估必备”?工具商与资本的逻辑
与头部公司的“低调实践”不同,行业层面对“评估”的推崇几乎到了“必修课”的程度。评估工具厂商(如Weights & Biases、Hugging Face Evaluate)和风险投资人是这场“评估运动”的主要推动者。
工具厂商的逻辑不难理解:评估是他们的核心产品。某评估工具公司CEO在TechCrunch采访中直言:“我们的顶级客户(包括FAANG)都在用系统化评估优化模型,你不做就会落后。”他们强调,评估能帮助企业“量化迭代效果”“控制黑箱风险”,甚至引用数据称“采用全面评估的企业故障率降低30%”。
资本的推动则更现实:风险投资人需要“可衡量的确定性”。对于VC而言,AI项目的“黑箱属性”本身已带来高风险,若团队连评估指标都无法提供,很难证明项目的可控性。正如某知名风投合伙人所言:“我们不投‘拍脑袋’的AI项目——评估是验证价值的唯一抓手。”
这种“必评估”的宣传,逐渐让评估从“可选工具”变成了“入行门槛”——产品经理简历里若没有“设计评估体系”经验,工程师不懂“指标优化方法论”,似乎都成了“不合格”的证明。
4. 评估的“阶段论”:0-to-1与成熟阶段的不同答案
Swyx的核心洞见在于:评估的价值并非绝对,而是取决于项目所处的阶段。他在推文中提出,0-to-1初创阶段与成熟扩展阶段对评估的需求截然不同,甚至可能“反向相关”。
表:AI项目不同阶段的评估需求对比
| 阶段 | 评估需求强度 | 核心目标 | 典型评估方式 | 风险点 |
|---|---|---|---|---|
| 0-to-1初创 | 低/可选 | 验证用户价值,快速试错 | 用户反馈、A/B测试(轻量级) | 过度评估抑制创新,错失机会 |
| 成熟扩展 | 高/必需 | 优化性能,控制风险,规模化落地 | 系统化指标测试、合规性评估 | 缺乏评估导致性能波动、合规风险 |
0-to-1阶段:评估可能成为“创新枷锁”。行业调研显示,约50%的AI初创团队反馈“早期过度评估拖慢了迭代速度”。例如,某对话式AI创业公司曾花3个月搭建评估体系,测试“回复准确率”“情感匹配度”等10余项指标,结果上线后发现用户更在意“响应速度”和“解决问题的直接性”——前期的评估完全偏离了真实需求。
成熟扩展阶段:评估是“稳定器”。当产品已验证用户价值,进入规模化阶段时,评估则变得不可或缺。例如,GPT-4在公开前进行了多轮“红队评估”(对抗性测试),以降低偏见、错误信息等风险;国内某AI大模型厂商在To B落地时,针对金融、医疗等行业定制了“合规评估模板”,确保输出符合监管要求。
5. 评估技能的新门槛:从“要不要”到“如何做”
尽管存在阶段差异,Swyx仍断言:评估正在成为AI从业者的新“硬技能”,其重要性堪比上一代产品经理必备的SQL、Excel。这并非指“所有人都必须做复杂评估”,而是“必须理解评估的逻辑,知道在什么阶段用什么工具”。
例如,0-to-1阶段的团队可以掌握“轻量级评估框架”:
- 用户反馈优先:通过访谈、问卷直接收集“是否解决问题”“是否愿意推荐”等主观评价;
- 最小化指标:只关注1-2个核心指标(如“用户留存率”“任务完成率”),避免陷入“指标迷宫”;
- 快速迭代测试:用A/B测试对比不同模型版本的实际效果,而非依赖离线跑分。
而成熟阶段的团队则需要系统化能力:
- 构建评估体系:覆盖性能(准确率、效率)、安全(偏见、毒性)、合规(数据隐私、透明度)等多维度;
- 自动化工具链:使用Weights & Biases、LangSmith等工具实现评估流程自动化,降低重复工作;
- 动态指标调整:根据业务场景更新评估标准(如电商客服AI更关注“问题解决率”,而教育AI更关注“知识准确性”)。
6. 未来的平衡之道:让评估服务创新而非束缚
AI评估悖论的本质,是**“指标驱动”与“价值驱动”的博弈**。头部公司的“不评估”并非否定评估本身,而是拒绝让僵化的指标取代对用户价值的敏感;行业的“必评估”呼吁也非虚言,只是需要结合阶段需求灵活落地。
未来的AI开发,或许需要一种“动态评估思维”:初创团队不必因“不会评估”而焦虑,成熟企业也不能用“评估指标”替代对创新的追求。正如Swyx在推文结尾所言:“评估的终极价值,是帮助我们更好地创造用户价值——而不是成为衡量‘谁更专业’的奖杯。”
对于行业而言,真正的进步或许在于:评估工具商能提供“阶段适配方案”,资本能容忍早期的“不完美评估”,而从业者能在“试错”与“优化”之间找到属于自己的节奏。
评论