MoE[12]
MiniMax发布开源大模型MiniMax-M2:Agentic工具调用能力比肩GPT-5/Claude,登顶开源LLM智能榜首
2025年10月MiniMax发布开源大语言模型MiniMax-M2,MIT许可证实现企业低门槛部署,兼容主流API与框架。其Agentic工具调用能力接近GPT-5、Claude,多项评测突破开源瓶颈,采用稀疏MoE架构平衡性能与效率,综合智能居开源首位,助力企业低成本构建高性价比智能自动化系统。

Wan2.2视频模型发布:AI视频生成迈入电影级美学与720P高效输出新阶段
2025年9月,Wan-AI团队发布Wan2.2基础视频模型,采用MoE架构解决"高质量与高效率"核心矛盾,结合电影级美学数据集与50亿参数模型,将720P@24fps高清视频生成带入消费级硬件时代。支持角色动画、音频驱动,开源生态完善,重新定义AI视频创作边界。

阿里巴巴发布通义DeepResearch:全球首个完全开源Web Agent,300亿参数(激活30亿)实现OpenAI级性能
阿里巴巴通义实验室发布全球首个完全开源Web Agent通义DeepResearch,以"小参数撬动高性能"引发关注。其采用MoE架构,300亿总参数推理仅激活30亿,实现与OpenAI同类产品相当能力,代码及权重全开源且允许商用,三大权威基准验证性能,推动Web Agent普及落地。
全球大模型开源生态报告2.0发布:中美贡献超四成核心力量,AI编程工具爆发式增长
《全球大模型开源开发生态全景与趋势报告2.0》发布,蚂蚁开源联合Inclusion AI勾勒AI开源生态。数据显示,62%核心项目诞生于“GPT时刻”后,平均年龄30个月,迭代加速至2-3个月;中美开发者贡献超40%,成“双核引擎”。技术上,MoE架构突破参数瓶颈,多模态成主流,AI编程工具爆发重塑开发流程,中国以开放权重策略推动生态创新。
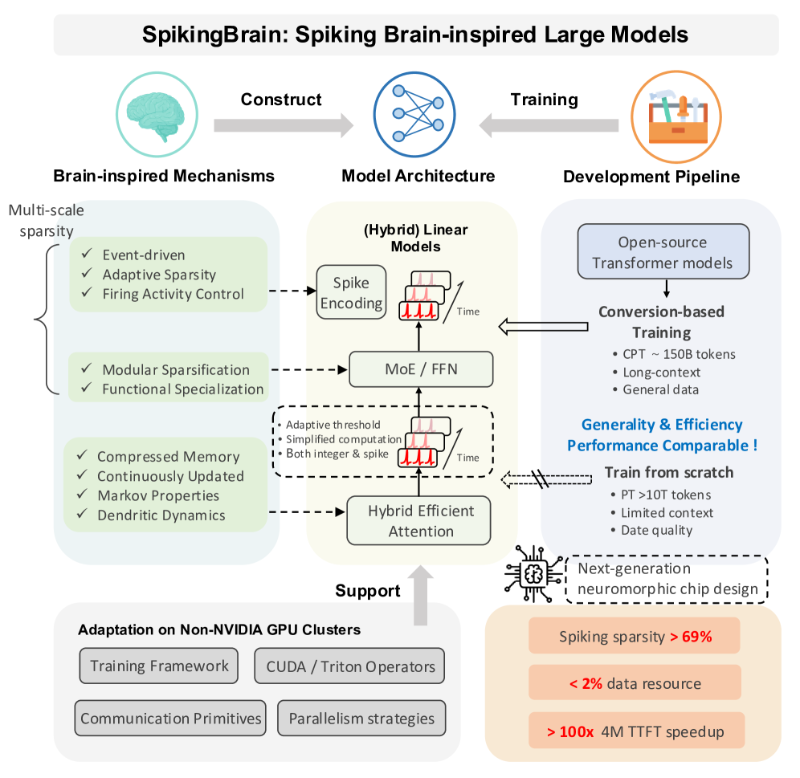
脑启发式大模型SpikingBrain发布:长序列处理提速百倍 能效优化破Transformer瓶颈
中国团队研发的SpikingBrain脑启发大模型,突破LLM长上下文处理瓶颈,通过脑启发脉冲计算、线性注意力机制及动态路由MoE结构,实现百倍推理加速与97.7%能耗降低。支持4M-token超长文本分析,适配法律、医疗及边缘计算场景,依托国产MetaX硬件平台,为非Transformer架构LLM提供自主可控高效方案。
Transformer发明者Vaswani:闭源AI阻碍创新,Essential AI力推西方版DeepSeek
Transformer之父Ashish Vaswani带领Essential AI从商业项目转向开源基础AI研究,破解行业闭源困境。对标中国DeepSeek,以MoE架构推动“高性能+低成本”模型研发,通过“交叉补贴”模式保障开源可持续,助力AI从技术垄断走向科学共享,加速实现AI普惠。
百度ERNIE-4.5-21B-A3B-Thinking登顶HuggingFace文本模型趋势榜
百度ERNIE-4.5-21B-A3B-Thinking登顶HuggingFace全球文本模型趋势榜,总榜位列第三,中国AI技术再获国际认可。该模型采用MoE架构与稀疏激活设计,210亿总参数仅激活30亿,实现轻量高性能。支持128K长上下文(约25万字)及高效工具调用,开源降低应用门槛,推动金融、医疗等复杂场景落地。
蚂蚁集团与人大联合发布业界首个原生MoE架构扩散语言模型LLaDA-MoE 即将开源
蚂蚁集团与人大联合研发业界首个原生MoE架构dLLM——LLaDA-MoE。该模型基于20TB数据训练,性能比肩主流自回归模型,推理速度有数倍优势,即将完全开源。其融合动态路由与扩散机制,在代码生成、数学推理等任务表现突出,为AI领域提供新研究方向与高效解决方案。
阿里通义千问Qwen3-30B MoE量化版发布:消费级硬件实现本地部署
近日,Hugging Face社区正式推出Qwen3-30B-A3B-Instruct-2507-MXFP4_MOE模型,这一基于阿里通义千问Qwen3架构的量化版本,以17.1GB的文件体积和30.5B参数量,在保持高性能的同时将大型MoE模型的硬件门槛拉至新低点。
智谱AI GLM-4.5登顶伯克利工具调用榜单 性能领先成本仅Claude 1.4%
【GLM-4.5开源大模型登顶伯克利工具调用榜单,AI编程性价比新标杆】智谱AI发布的GLM-4.5大模型在伯克利工具调用排行榜中以94.3%任务完成率超越Claude Opus 4.1(91.2%),运行成本仅为其1.4%,推理速度达280 tokens/秒(Claude Opus 4.1为93 tokens/秒),成当前性价比领先的AI编程解决方案。该模型采用MoE架构,动态激活专家网络提升效率,支持Python、Java等10余种编程语言跨文件调用,已集成VS Code、IntelliJ等IDE插件,覆盖代码生成、调试全流程。开源特性使企业部署成本压缩90%以上,中小团队与开发者可低成本接入顶级AI编程能力,推动行业工具调用效率与成本平衡革新。