
1. 长上下文处理成LLM发展拦路虎,脑启发模型带来新突破
在大语言模型(LLM)的发展赛道上,长上下文处理能力和能效优化一直是两大绕不开的“拦路虎”。传统Transformer架构在处理超长文本时,计算量随序列长度呈二次方增长,推理内存也线性攀升,导致4M-token级别的长文档分析、多轮对话记忆等场景变得“又慢又费电”。而近日,由中国科学院自动化研究所、北京脑启发通用智能大模型重点实验室与MetaX集成电路公司联合研发的SpikingBrain脑启发大模型,通过模拟生物神经元的脉冲式计算机制,结合国产MetaX硬件平台,一举实现了长上下文效率的百倍提升与低功耗运行,为行业带来了非Transformer架构的全新可能。
2. SpikingBrain的技术内核:从生物神经元到线性复杂度计算
要理解SpikingBrain为何能突破Transformer的瓶颈,首先需要看向它的“脑启发”内核。与传统LLM依赖的密集型计算不同,SpikingBrain模拟了生物大脑中神经元的“脉冲发放”机制——只有当输入信号达到一定阈值时,神经元才会被激活并传递脉冲,这种“事件驱动”的特性天然具备稀疏计算优势。
2.1 从“全连接”到“事件驱动”:重构注意力机制
Transformer的核心痛点在于Softmax注意力的二次方复杂度(O(n²)),而SpikingBrain通过三种注意力机制的融合,将复杂度降至线性(O(n))或混合线性:
- 滑动窗口注意力(SWA):聚焦局部上下文,避免全局遍历带来的算力浪费;
- 线性注意力(Linear Attention):通过核函数优化,将注意力计算从矩阵乘法转为逐元素操作;
- 混合注意力(Hybrid Attention):根据序列长度动态切换机制,在长序列时优先启用线性模式(如7B版本默认线性,76B版本支持混合模式)。
Tips:什么是“内生复杂性”理论?
SpikingBrain的设计基于神经科学中的“内生复杂性”理论,即生物神经系统通过神经元的动态交互(而非固定连接)处理信息。模型将这种特性转化为“树突计算简化形式”,通过脉冲发放的时间差和强度传递上下文关联,替代传统Transformer的静态权重矩阵。
2.2 专家混合模型(MoE)的动态路由
除了注意力优化,SpikingBrain还集成了MoE结构,通过“动态路由”机制将输入分配给最相关的“专家模块”。与传统MoE不同,其专家选择依赖脉冲信号的稀疏分布——只有激活强度最高的少数专家会参与计算,进一步降低无效能耗。这种“按需调用”的模式,让7B模型在处理长序列时仍能保持高效。
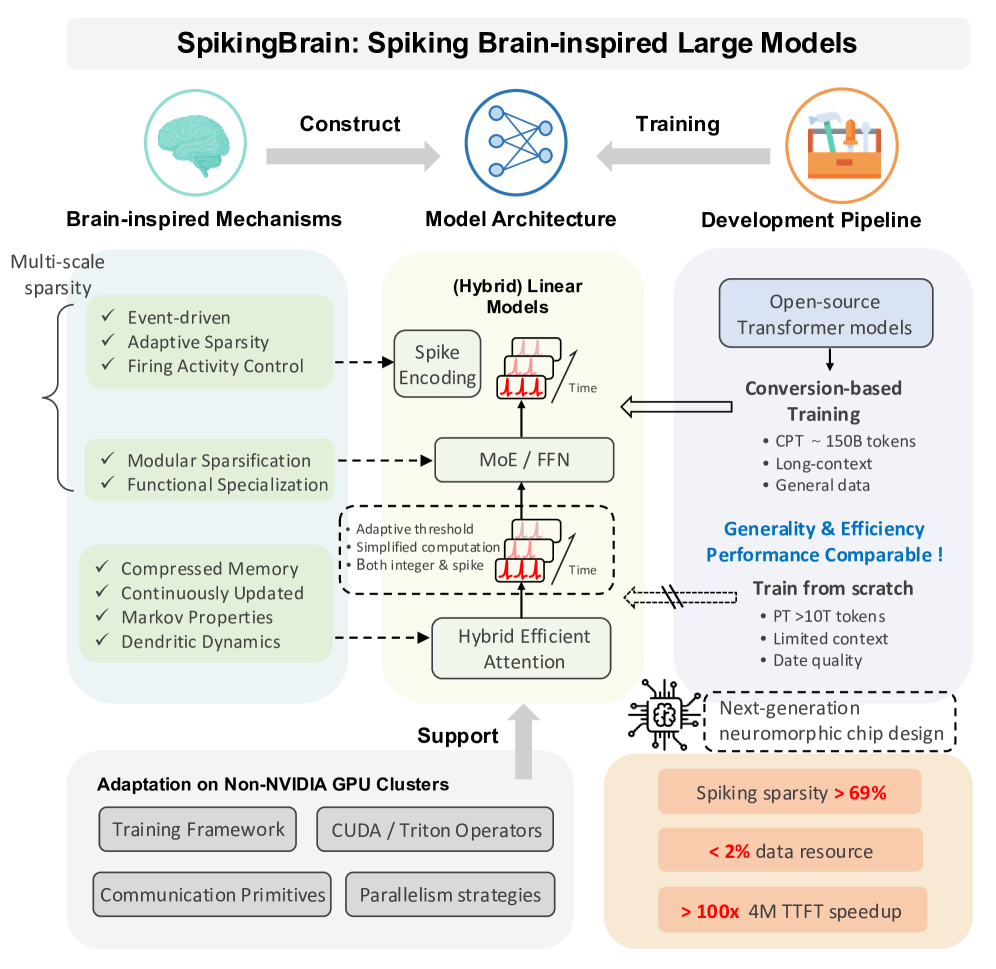
为更清晰展现脑启发机制向模型架构的转化,我们可以参考这张 SpikingBrain 的技术架构图。从图中能看到,左侧 “Brain - inspired Mechanisms(脑启发机制)” 里,多尺度稀疏性(如事件驱动、自适应稀疏等)、压缩记忆等特性,通过 “Construct(构建)” 过程,融入到中间 “Model Architecture(模型架构)” 的脉冲编码、MoE/FFN、混合高效注意力等模块中。同时,右侧 “Development Pipeline(开发流程)” 里的训练方式,又反向支持模型架构的优化,最终让 SpikingBrain 在性能与效率上实现突破,比如能达成超过 69% 的脉冲稀疏度、利用小于 2% 的数据资源等,这些都为其线性复杂度计算等技术优势提供了支撑。
3. 训练范式与硬件协同:两阶段课程策略如何提升效率
高效的模型离不开创新的训练方法与硬件支持。SpikingBrain采用“两阶段课程式训练”策略,结合MetaX国产GPU集群,实现了大规模分布式训练的高利用率。
3.1 从“暴力训练”到“渐进优化”:两阶段课程策略
传统LLM训练常因数据分布不均导致收敛缓慢,而SpikingBrain的训练流程分为:
- 多阶段转换流水线:先在短序列数据上训练基础能力,再逐步扩展至长序列(如从1K-token到4M-token),减少早期无效计算;
- MoE升级(Upcycling):随着训练深入,动态调整专家模块的数量和权重,让旧专家“知识”迁移至新模块,避免资源浪费;
- 脉冲驱动训练:通过自适应阈值控制脉冲发放频率,让模型在训练中自然学习“何时激活、激活多少”,最终形成69.15%的稀疏度(即仅30.85%的神经元参与计算)。
3.2 MetaX硬件集群的“四维并行”支持
训练的高效落地离不开硬件支撑。SpikingBrain-7B模型在数百块MetaX C550 GPU上稳定运行数周,其秘诀在于“四维并行”拓扑策略:
- 数据并行:将训练数据分片,多GPU同时计算;
- 流水线并行:按层拆分模型,不同GPU负责不同网络层的计算;
- 专家并行:MoE的专家模块分布在不同GPU,动态调度资源;
- 序列并行:长序列按位置拆分,降低单卡内存压力。
这种协同让模型FLOPs利用率(MFU)达到23.4%,远超行业平均的15%-20%,意味着硬件资源被更充分地利用。
4. 实测性能解析:百倍加速、高稀疏度与低功耗并行
实验室数据最能直观体现SpikingBrain的优势。在4M-token长序列测试中,其核心性能指标如下:
4.1 百倍TTFT加速:长序列推理的“响应革命”
对于长文本处理,用户最直观的体验是“第一个token何时生成”(TTFT)。传统7B模型处理4M-token时,TTFT常需数十秒,而SpikingBrain-7B实现了超过100倍加速,响应时间从“分钟级”压缩至“秒级”。这得益于两点:
- 事件驱动推理:输入序列中只有关键信息会触发脉冲计算,跳过冗余文本;
- 恒定内存分配:推理阶段预分配固定内存,避免动态扩容的时间损耗。
4.2 69.15%稀疏度与能耗优势
高稀疏度直接带来低功耗。实测显示,SpikingBrain的乘加运算能耗较传统FP16精度降低97.7%,较INT8量化降低85.2%。以下为核心性能汇总表:
| 模型版本 | TTFT加速倍数 | 稀疏度(%) | MFU(%) | 支持GPU数量 |
|---|---|---|---|---|
| SpikingBrain-7B | 100× | 69.15 | 23.4 | 100+ |
| SpikingBrain-76B | —— | —— | —— | 100+ |
注:TTFT(Time to First Token)为首个token生成时间,MFU(Model FLOPs Utilization)为模型算力利用率。
4.3 开源生态:从模型到部署工具
为推动技术落地,SpikingBrain-7B已开源,同步提供Triton算子库、脉冲可视化接口和分布分析工具。开发者可通过这些工具查看神经元激活状态,进一步优化模型稀疏度和硬件适配。
5. 从实验室到产业落地:适配场景与自主可控价值
SpikingBrain的突破不仅是技术创新,更具备明确的产业价值。其事件驱动和低功耗特性,让LLM在更多场景从“不可能”变为“可能”。
5.1 高复杂度场景:法律、医疗与多智能体模拟
在法律文档分析(如百万字合同审查)、医学影像报告解读(长文本+专业术语)等场景,SpikingBrain的长上下文处理能力可显著提升效率。此外,多智能体模拟(如自动驾驶中的多车协同决策)需要实时处理海量传感器数据,其低延迟特性也能发挥优势。
5.2 边缘计算与低功耗设备
传统LLM因高能耗难以部署在边缘设备(如工业传感器、移动终端),而SpikingBrain的稀疏计算模式使其能在低功耗芯片上运行。例如,在智能制造中,边缘设备可通过轻量化SpikingBrain模型实时分析生产线数据,无需依赖云端算力。
5.3 自主可控的技术路径
值得关注的是,SpikingBrain全程基于国产MetaX GPU集群训练,是首次在千卡级国产硬件平台验证的类脑脉冲大模型。这不仅打破了国外GPU对大模型训练的垄断,也为神经形态芯片(模拟大脑神经元结构的专用芯片)设计提供了理论支撑。
6. 非Transformer架构的未来
SpikingBrain的发布,标志着非Transformer架构开始在LLM领域崭露头角。其意义不仅在于“效率提升”,更在于为通用人工智能(AGI)提供了新范式——从“模仿人类智能的结果”转向“模仿人类智能的过程”(即生物神经系统的动态处理机制)。
未来,随着脉冲神经网络与异构硬件的融合,我们可能看到:
- 神经形态芯片的普及:专用硬件进一步放大事件驱动计算的能效优势;
- 多模态脉冲模型:将文本、图像、语音的处理统一到脉冲框架下;
- 脑机接口的桥梁:脉冲信号的生物兼容性,为AI与大脑直接交互奠定基础。
评论