人工智能[48]
挑战AI规模路线:研究员称首个超级智能将是“超人学习者”
人工智能领域“规模至上”路线遇瓶颈,前OpenAI团队创立的Thinking Machines Lab提出“超人学习者”新范式,主张通过主动探索、知识内化突破被动训练与灾难性遗忘局限,其STAR算法较GPT-4任务完成率提升37%,或成通用人工智能(AGI)关键进化方向。

苹果休斯顿工厂提前出货AI服务器 支撑Apple Intelligence及私有云核心算力
苹果AI赛道布局提速,其美国休斯顿新工厂已提前启动AI服务器出货,较原计划大幅提前。依托美国CHIPS法案及德州补贴,叠加与台积电合作实现供应链周期压缩,该工厂为Apple Intelligence平台及私有云计算注入核心算力。其端云协同架构通过定向传输技术实现数据隐私与算力平衡,或将为行业树立算力、隐私、安全三位一体新标准。
"Transformer之父"Jones:我已厌倦,行业沉迷或阻碍下一个突破
Transformer架构共同作者Llion Jones警告,AI行业正陷Transformer路径依赖,过度依赖单一架构致创新停滞。其虽为大模型基础,但存计算成本高、泛化能力弱等局限。目前Hyena Hierarchy、Mamba等替代技术涌现,Sakana AI等机构正探索生物/物理启发新路径,呼吁行业重建自由探索生态,突破创新瓶颈。
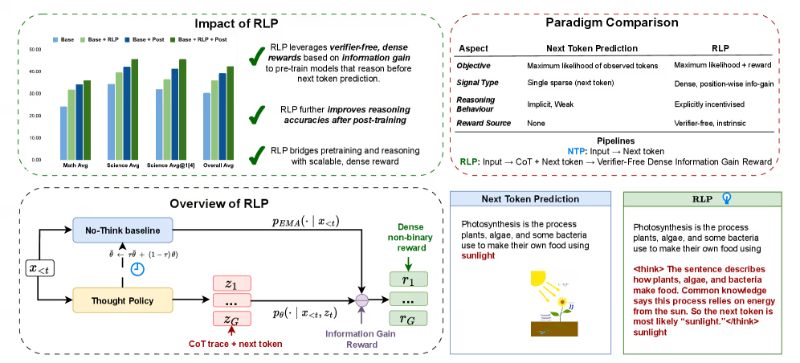
英伟达RLP技术重塑大模型预训练:让AI在预训练阶段“先思考后预测”,推理能力显著提升
英伟达推出的RLP(强化学习预训练)技术,革新AI大模型推理能力培养范式。传统模型依赖后训练微调,存在效率低、易"灾难性遗忘"问题,而RLP在预训练阶段嵌入强化学习,通过"生成思考-增强预测-奖励反馈"闭环,让模型学会"先思考后预测"。实验显示,小模型推理能力提升17%,中模型达35%,且降低人工标注成本,金融、法律等场景多步决策错误率直降30%,实现预训练与后训练效果叠加。
三星AI发布TRM模型:700万参数挑战大模型神话
三星SAIT研发的700万参数Tiny Recursion Model(TRM)模型,在数独、迷宫等结构化推理任务中性能超越参数规模达其万倍的顶尖大模型,颠覆"越大越强"行业认知。其核心通过"单层神经网络+递归循环"机制模拟深度思考,以极简架构实现高效推理,为低成本AI研发提供新思路,凸显参数效率与机制创新价值,推动AI技术路径多元化发展。

ASCII绘图板上线:AI辅助开发,专注纯手工文本艺术创作体验
ASCII绘图板是一款反AI自动化、主打手动创作的文本艺术工具,为爱好者提供自定义ASCII画笔、可调画布及文本导出功能,通过字符排列融合形成独特纹理化图案。虽由LLM辅助开发,却专注手工创作过程,让用户重拾ASCII艺术的创作温度,适合打造个性化文本艺术作品。
OpenAI Stargate项目投资500亿美元:350亿专攻AI芯片,打造111吉瓦超级算力中心
OpenAI代号“Stargate”的超级数据中心项目,计划投资500亿美元打造1GW全球顶级算力,其中350亿专项用于AI芯片采购,占比达70%,凸显AI基础设施“烧钱”本质。该项目推动全球算力竞赛升级,2030年全球AI基建投资或破1.1万亿美元,算力成科技竞争力核心,行业正迎来芯片采购与自研的战略分化。
日本制造业AI变革:ENEOS Materials率先引入ChatGPT Enterprise提升效率
日本制造业面临劳动力短缺、老龄化及原材料成本攀升压力,转型迫在眉睫。ENEOS Materials率先全面引入ChatGPT Enterprise,以生成式AI重构研发、工程、人力资源等关键流程,破解跨国研发壁垒、提升设计效率,成为行业智能化转型标杆,彰显AI驱动制造业效能跃升的核心价值。
Gensyn发布多项前沿研究 推动机器智能网络迈向开放未来
AI行业面临算力垄断与可信协作难题,Gensyn构建去中心化机器智能协议,融合区块链与分布式机器学习技术,通过概率性审计机制与双代币模型解决验证效率与安全痛点,激活全球闲置算力,已在医疗联合建模、制造业多智能体协同等场景落地,推动AI技术开放普惠发展。
CMU研究:数据受限环境下扩散模型表现优于自回归模型
AI领域高质量数据增长速度已落后算力提升,数据危机加速逼近。卡内基梅隆大学研究显示,在数据稀缺但算力充足场景下,扩散模型性能显著超越长期主导生成任务的自回归模型。其“加噪-去噪”的隐式数据增强机制,能提升数据利用率,为生物医学等数据稀缺领域模型选型、数据策略调整提供新路径。