
在AI大模型向复杂任务进军的过程中,推理能力始终是衡量智能水平的核心标尺。传统大模型往往需要在预训练后依赖大量人工标注数据进行微调,才能勉强掌握多步推理逻辑,这种“先记忆、后思考”的模式不仅效率低下,还常常出现“学了新技能忘了旧知识”的尴尬。而英伟达近日推出的“强化学习预训练”(RLP)技术,正试图从源头改写这一规则——让模型在预训练阶段就主动学会“先思考后预测”,为AI推理能力的培养开辟了全新路径。
1. 传统训练范式的困境:推理能力为何成“后知后觉”的技能?
当前大模型的成长路径几乎遵循固定剧本:先在海量文本中进行“下一个词元预测”的预训练,像海绵一样吸收语法、事实和基本关联;随后进入监督微调(SFT)或人类反馈强化学习(RLHF)等后训练阶段,通过高质量标注数据(如链式思考样本)学习复杂推理。但这种线性流程与人类认知存在本质差异——人类理解信息时会即时调动已有知识进行整合分析,而非逐词被动记忆。
这种差异直接导致两大瓶颈:一是预训练阶段缺乏推理机制,模型难以建立深层逻辑关联,后续微调时需“从零学起”;二是后训练依赖大量人工标注数据(如ChatGPT的RLHF需人类反馈数据),成本高昂且易出现“灾难性遗忘”——微调阶段习得的推理能力可能覆盖预训练的基础能力。正如英伟达研究团队在论文中指出:“让模型在预训练时只学‘记忆’,却要求它在后训练时突然掌握‘推理’,这如同让一个从未做过数学题的人直接解微积分。”
2. RLP技术核心:让AI在预训练时就学会“有用的思考”
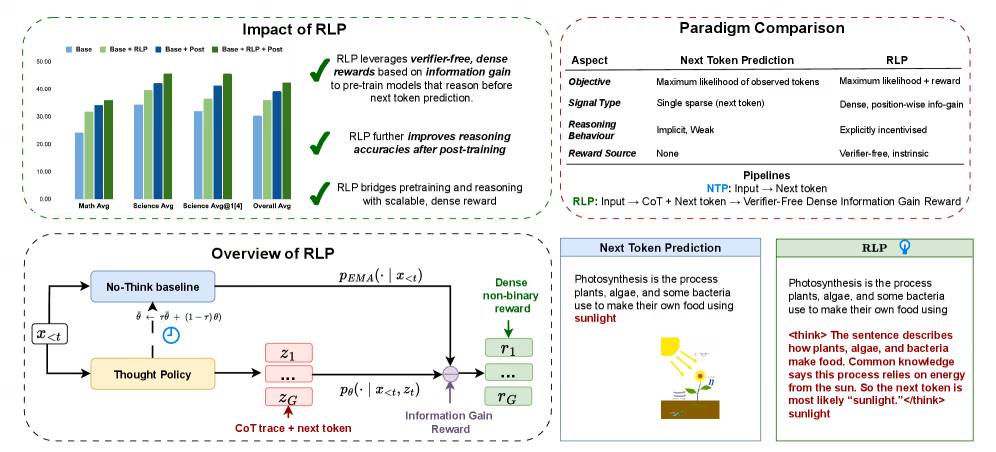
传统“下一个词元预测”(NTP)仅依赖单点、稀疏的“正确 token”信号,模型被动记忆;RLP 则在每一步都引入密集、逐位置的“信息增益”奖励,显式激励模型先产生简短思考链(CoT trace),再用改进后的概率去预测。奖励值由 log P_new – log P_old 自动计算,无需人工标注或外部 verifier,实现了“无监督推理”的自监督循环。
RLP(Reinforcement Learning Pre-training)技术的突破,在于将强化学习的核心逻辑——“奖励引导行为”——首次深度嵌入预训练环节。与传统预训练仅关注“预测正确答案”不同,RLP让模型在每次预测前先进行“内部思考”,并通过奖励机制判断这种思考是否“有用”,从而逐步内化推理能力。
2.1 三步流程:从“思考”到“预测”的闭环
RLP的运作机制可概括为“生成思考-增强预测-奖励反馈”的循环:
- 内部推理链生成:模型在预测下一个词元前,会主动生成一段简短的“思考链”(如解答数学题时的分步推导),平均长度控制在5词元以内,避免无效计算。
- 上下文增强预测:将原始文本与新生成的思考链结合,作为扩展上下文输入模型,再进行词元预测。
- 自适应奖励机制:通过数学公式
r = log(P_new) - log(P_old)计算奖励——其中P_new是结合思考链后的预测概率,P_old是无思考链时的概率。只有当思考链提升预测准确性(即r>0)时,模型才获得正反馈,反之则无奖励。
Tips:强化学习中的“奖励函数”是引导模型行为的核心。RLP的奖励设计巧妙之处在于“自监督”——无需人工标注思考链是否正确,仅通过预测概率变化判断思考是否有效,既降低了数据依赖,又确保奖励与预训练目标(准确预测)高度一致。
2.2 训练稳定性保障:在“思考”与“记忆”间找平衡
为避免模型过度沉迷“思考”而偏离预训练目标,RLP引入两项关键约束:一是通过策略梯度优化控制思考链长度,确保简洁高效;二是采用KL散度约束,限制思考链生成分布与原始文本分布的偏离程度,防止模型“胡思乱想”。这种设计让RLP在强化推理能力的同时,不影响基础语言理解能力的习得。
3. 性能实测:推理能力跃升40%,效率与效果双突破
英伟达在Qwen3-1.7B(小模型)和Nemotron-Nano-12B(中模型)上的实验,印证了RLP的显著优势。无论是推理能力提升幅度,还是训练效率,RLP都展现出对传统方法的超越。
3.1 核心数据对比:小模型“逆袭”,中模型“飞跃”
在小模型Qwen3-1.7B上,RLP相比标准预训练提升17%的推理能力,且效果优于专门优化推理的RPT(前缀奖励法);在中模型Nemotron-Nano-12B上,仅用极少量数据,RLP就实现了35%的相对性能提升。更关键的是,RLP赋予的推理能力不会被后续微调“冲刷”——经过SFT或RLHF后,模型仍能保留7%-8%的额外增益,实现“预训练+后训练”效果叠加。
3.2 横向对比:RLP如何重塑训练成本结构?
与传统方法相比,RLP的效率优势体现在对人工标注数据的“降依赖”上。斯坦福大学的评估显示,RLP构建推理能力的速度比“标准预训练+RLHF”流程快40%以上,且无需人类反馈数据或高质量推理样本,仅依赖原始文本即可。以下是三种主流训练方法的核心差异:
| 方法 | 推理能力培养阶段 | 数据依赖 | 训练成本 |
|---|---|---|---|
| 标准预训练 | 后训练微调 | 需人工标注推理样本 | 高(多阶段迭代) |
| RLHF(如ChatGPT) | 后训练阶段 | 依赖人类反馈数据 | 极高(奖励模型+RL) |
| RLP | 预训练阶段内化 | 原始文本+自监督奖励 | 中(单阶段集成) |
4. 企业级应用:从金融分析到法律合同,多步决策错误率直降30%
RLP技术的落地价值在复杂决策场景中尤为突出。摩根士丹利AI实验室测试显示,基于RLP预训练的模型在金融收益预测任务中,多步推理错误率降低28%;法律AI平台Lexion则发现,RLP模型解析合同条款冲突时,召回率从77%提升至92%,误报率下降15%。这些场景的共性在于需要“多步逻辑推导”——如从市场数据到收益预测需考虑政策、行业、公司财务等多层因素,传统模型易在中间环节出错,而RLP预训练的“思考习惯”能帮助模型更稳定地完成链条式推理。
5. 行业反馈与技术边界:RLP是“银弹”还是“新起点”?
RLP的突破引发了学术界与产业界的广泛讨论。英伟达应用深度学习研究副总裁Bryan Catanzaro强调:“RLP不是为了取代微调,而是让模型带着更强的‘推理基因’进入后训练阶段,事半功倍。” 但技术并非完美——Meta的对比报告指出,RLP在参数小于1B的小模型上效果有限,主要受益于中大型模型;DeepMind则认为,RLP的奖励机制依赖“即时预测概率”,对需要长期推理(如多轮数学证明)的任务支持不足,需结合外部验证器优化。
Yann LeCun在推文中评价:“RLP是预训练目标多样化的关键一步,但要实现通用人工智能(AGI),还需与模块化推理架构结合——让模型不仅会‘思考’,还能‘规划思考路径’。”
6. 预训练范式革新:从“单一目标”到“多能力协同”
RLP技术的真正意义,在于打破了大模型预训练“唯下一个词元预测”的单一目标。传统预训练如同让模型“死记硬背”,而RLP则赋予它“边学边想”的能力。未来,预训练可能融合更多目标——如事实准确性判断、多模态关联推理等,让模型在早期就构建更全面的“智能地基”。
随着RLP的落地,AI训练正从“分段式优化”走向“全周期协同”。对于企业而言,这意味着更低的标注成本、更高的部署效率;对于AI行业而言,这或许是迈向“类人认知”的重要一步——毕竟,真正的智能从不只是“记住答案”,而是“学会思考”。
评论