大语言模型[119]
Gartner预测:AI聊天机器人将致传统搜索流量降25%,Geostar以GEO技术引领企业应对
AI聊天机器人普及正冲击传统SEO,Gartner预测2026年传统搜索引擎流量将锐减25%。初创公司Geostar推出生成式引擎优化(GEO)技术,通过AI驱动自动化方案,助力企业适应AI主导的搜索新范式,成为数字营销领域关注焦点。

MiniMax发布开源大模型MiniMax-M2:Agentic工具调用能力比肩GPT-5/Claude,登顶开源LLM智能榜首
2025年10月MiniMax发布开源大语言模型MiniMax-M2,MIT许可证实现企业低门槛部署,兼容主流API与框架。其Agentic工具调用能力接近GPT-5、Claude,多项评测突破开源瓶颈,采用稀疏MoE架构平衡性能与效率,综合智能居开源首位,助力企业低成本构建高性价比智能自动化系统。

Anthropic免费开放Claude Haiku 4.5:高性能低成本挑战OpenAI
Anthropic免费开放Claude Haiku 4.5轻量级AI模型,编码能力达75.2%接近Sonnet 4,速度提升两倍、成本仅三分之一,大幅降低企业应用门槛。其“免费高性能+多智能体架构”策略挑战OpenAI,推动AI行业竞争转向生态整合与ROI,沃尔玛等企业已落地应用。
Together AI发布ATLAS自适应推测器:实时学习工作负载,AI推理速度提升400%
在AI大模型推理中,静态优化难应对动态负载,Together AI推出的ATLAS自适应推测器通过双架构协同与实时学习,将推理速度提升400%,在通用GPU上实现对专用芯片的性能追赶。该技术破解动态场景难题,为企业级AI部署提供“以软代硬”新路径,助力降本提效。
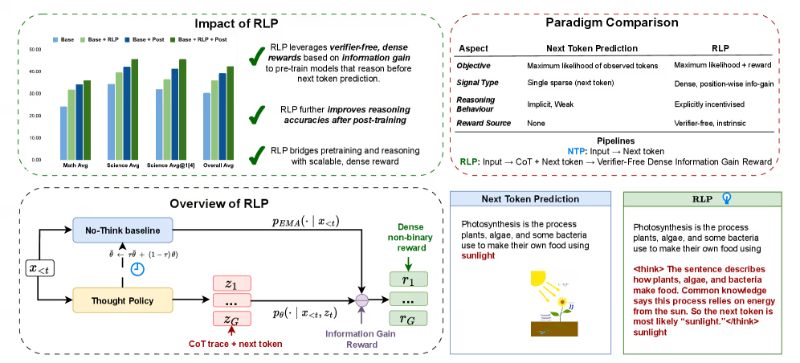
英伟达RLP技术重塑大模型预训练:让AI在预训练阶段“先思考后预测”,推理能力显著提升
英伟达推出的RLP(强化学习预训练)技术,革新AI大模型推理能力培养范式。传统模型依赖后训练微调,存在效率低、易"灾难性遗忘"问题,而RLP在预训练阶段嵌入强化学习,通过"生成思考-增强预测-奖励反馈"闭环,让模型学会"先思考后预测"。实验显示,小模型推理能力提升17%,中模型达35%,且降低人工标注成本,金融、法律等场景多步决策错误率直降30%,实现预训练与后训练效果叠加。

Zendesk发布AI增强版Resolution平台 GPT-5与MCP技术驱动客户服务智能化升级
Zendesk 2025年推出AI增强版Resolution平台,集成GPT-5与MCP协议,实现多意图识别、动态上下文加载(数据延迟800ms),覆盖语音AI代理、视频通话等全场景功能。创新“按效果付费”模式,助力零售、电商等行业提升客服自动化率至89%,推动客户服务从工具向主导力量转型,成客服AI智能化标杆。

ASCII绘图板上线:AI辅助开发,专注纯手工文本艺术创作体验
ASCII绘图板是一款反AI自动化、主打手动创作的文本艺术工具,为爱好者提供自定义ASCII画笔、可调画布及文本导出功能,通过字符排列融合形成独特纹理化图案。虽由LLM辅助开发,却专注手工创作过程,让用户重拾ASCII艺术的创作温度,适合打造个性化文本艺术作品。

全球首个时间序列原生模态开源语言模型OpenTSLM发布:突破传统AI时间盲区,多任务效率提升超千倍
OpenTSLM是斯坦福大学等机构研发的首个原生时间序列语言模型,突破传统模型长序列处理效率低、LLM无法理解时序动态特征的瓶颈。通过创新交叉注意力架构,效率提升数百倍,实现临床级准确性,支持医疗等领域自然语言交互,已开源,开启“时间智能”新可能。

LLM驱动MCP服务器:Cloudflare“Code Mode”启发新一轮技术探索
AI驱动的自动化工作流正迎革新,Code Mode范式崛起:Cloudflare提出LLM生成TypeScript代码替代传统工具调用,结合Deno沙盒安全执行,提升工作流开发效率40%。开源项目codemode-mcp进一步融合MCP协议,探索"代码+工具"协同,推动复杂任务动态编排,重塑AI驱动任务处理模式。

微软Anthropic深化合作:Claude模型全面接入Microsoft 365 Copilot,企业级AI添新动能
2025年9月,Anthropic与微软宣布将Claude Sonnet 4、Opus 4.1集成至Microsoft 365 Copilot,标志企业级AI进入“多模型协同”阶段。Claude模型以安全合规、长上下文推理及灵活代理构建为核心优势,差异化满足高端复杂任务(如战略分析)与日常办公自动化需求,助力企业提升办公效率与智能化水平。