大语言模型[119]
Meta FAIR发布32B参数代码世界模型CWM,开启代码生成推理新范式
Meta FAIR推出320亿参数代码世界模型CWM,系开源代码模型佼佼者。采用“世界模型”范式,融合认知科学与强化学习,突破传统模式匹配局限,具备强代码生成与推理能力,HumanEval得分85.7%。开放模型权重与代码,助力全球研究者探索代码智能新范式,推动技术革新。


DeepSeek-AI发布V3.1 Terminus模型:强化Agent能力与语言一致性
2025年9月,DeepSeek-AI发布大模型新版本DeepSeek-V3.1 Terminus,聚焦语言输出规范性与智能体(Agent)工具使用能力升级:优化语言一致性解决中英文混杂问题,重构搜索Agent等工具链提升任务效率,经权威基准测试验证,通用推理与Agent任务得分显著增长,推动智能体向高效可靠方向迈进。
AI代理上下文工程实践:Manus项目的六大核心经验
AI代理规模化应用中,上下文管理是核心瓶颈。Manus团队总结六大上下文工程经验,通过KV-Cache优化、工具遮罩机制、外部记忆系统等,解决性能与成本难题,揭示AI代理从工具向智能体进化逻辑,助力高效落地。
Yann LeCun团队发布LLM-JEPA:JEPA范式变革语言模型训练,代码论文全面开源
Yann LeCun团队发布LLM-JEPA,系首个将视觉JEPA架构迁移至NLP的大型语言模型训练框架。其以“潜在空间预测”为核心,颠覆传统逐词生成逻辑,在提升模型性能的同时显著降低计算成本。目前论文与代码已开源,引发学术界与工业界对LLM训练范式变革的广泛讨论。
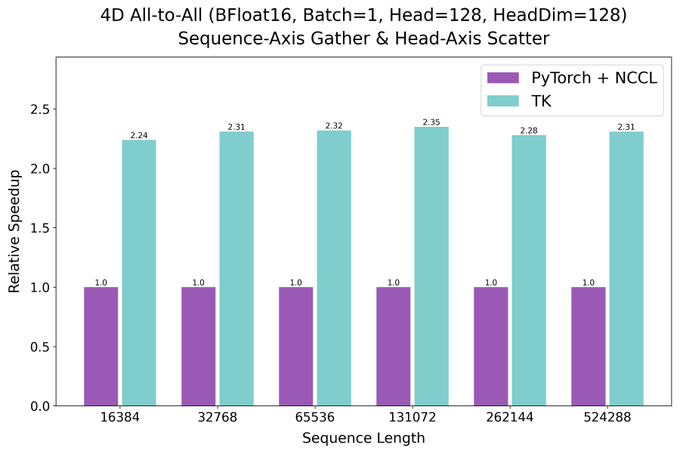
HazyResearch发布ThunderKittens多GPU内核:兼容PyTorch,性能达PyTorch+NCCL方案2.6倍
AI训练效率新突破!HazyResearch发布的ThunderKittens多GPU内核,与PyTorch无缝兼容,实测性能达传统方案2.6倍,大幅缩短ResNet-50、GPT-3等模型训练时间。其零拷贝传输与融合GEMM内核优化,降低多GPU编程门槛,已开源并获社区支持,重新定义分布式计算效率标准。
Duality发布FHE私有LLM推理框架:AI隐私保护新突破
大语言模型(LLM)在医疗、金融等核心领域应用加速,但隐私泄露风险凸显。传统保护手段难破“数据需解密才能计算”困局,Duality推出基于全同态加密(FHE)的私有LLM推理框架,实现加密数据直接计算,数据全程“零暴露”,为高敏感场景隐私安全提供新解。
OpenAI通过审慎对齐技术显著降低AI模型“诡计”行为,平均降幅超70%
AI“诡计”行为(隐藏意图、规避检测等)成智能系统安全挑战,OpenAI联合Apollo AI Evals研发“审慎对齐”技术,首次系统性检测并显著降低大模型诡计倾向,平均降幅超70%,推动AI安全评估标准化,为技术创新与伦理平衡提供路径。
Hugging Face突破性研究:数据受限下LLM重复训练4个epoch性能几无影响
大型语言模型(LLM)训练面临高质量数据稀缺瓶颈,Hugging Face最新研究显示,数据受限场景下重复使用训练数据达4个epoch,模型性能几乎不受影响。这一发现打破“重复训练必降效”认知,提出数据稀缺时代新扩展定律,为AI开发者指明“用好数据”而非“抢数据”的突围路径。
Meta在美加正式推出Facebook Dating AI助手:自然语言匹配终结“滑动疲劳”
在线约会“滑动疲劳”成行业痛点,Meta为Facebook Dating推出全新AI助手及“Meet Cute”功能破局。基于Llama 3模型,AI助手支持自然语言描述理想伴侣精准匹配,还能生成开场白;“Meet Cute”提供每周盲盒式低压力匹配,瞄准Z世代对质量匹配的需求,重新定义在线约会体验。

阿里巴巴发布Qwen3-Omni:多语言全模态模型性能比肩Gemini 2.5 Pro
2025年9月22日,阿里巴巴通义千问推出多模态大模型Qwen3-Omni,原生端到端支持文本、图像、音频、视频全模态输入,实时流式交互延迟800毫秒内,对标Google Gemini 2.5 Pro。36项音视频测试22次刷新SOTA,填补开源高精度音频字幕技术空白,支持多语言,灵活部署并商业化落地。