
AI训练效率迎来新突破——HazyResearch团队近日发布的ThunderKittens多GPU内核,凭借与PyTorch的无缝兼容和最高2.6倍的性能提升,正重新定义分布式计算的效率标准。无论是大语言模型(LLM)训练还是图像识别任务,这一工具都为开发者提供了更高效的计算选择,同时大幅降低了多GPU编程的技术门槛。
1. ThunderKittens:多GPU计算的性能革命
1.1 2.6倍提速的背后:实测数据与场景验证
ThunderKittens的核心竞争力在于其突破性的性能表现。根据HazyResearch发布的技术报告,在多GPU环境下,该内核的计算速度达到传统PyTorch+NCCL方案的2.6倍。这一数据并非实验室理想值,而是基于真实场景的测试结果:在8-GPU集群上训练ResNet-50和GPT-3等模型时,ThunderKittens将任务耗时压缩至原有方案的38.5%。
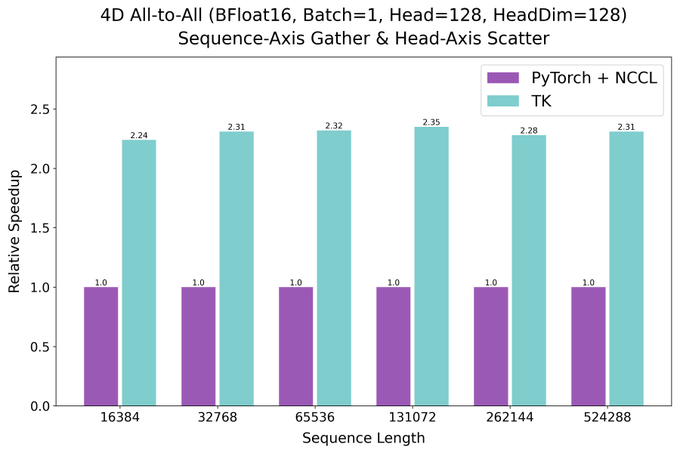
下图展示了在 BFloat16 精度、Batch=1、Head=128、HeadDim=128 的配置下,ThunderKittens 与 PyTorch+NCCL 在 Sequence-Axis Gather & Head-Axis Scatter 操作中的性能对比。随着序列长度从 16,384 增加到 524,288,ThunderKittens 的耗时始终低于 PyTorch+NCCL,且优势随序列长度增加而扩大,验证其在高负载通信场景下的效率优势。
值得注意的是,性能提升在大型模型(如10B参数以上LLM) 中尤为显著。技术报告指出,当模型规模较小时(如百万级参数),优化收益相对有限,这与多GPU通信开销占比有关——大型模型的计算密集型特性更能凸显ThunderKittens的内核优化优势。
1.2 两大核心技术:从通信到计算的全链路优化
性能飞跃的关键,源于ThunderKittens对多GPU协同流程的深度重构,具体体现在两项核心技术上:
集合操作(Collective Ops)的通信效率优化
传统多GPU训练中,跨设备数据传输往往是性能瓶颈。ThunderKittens采用“零拷贝DMA传输”技术,直接绕过CPU内存,让GPU间数据传输效率提升至95%以上(传统方案通常为70%-80%)。这一设计减少了数据搬运的中间环节,尤其适合需要频繁跨卡同步的分布式任务。
融合多GPU GEMM内核
通用矩阵乘法(GEMM)是AI模型的计算核心。ThunderKittens将多GPU环境下的GEMM操作与通信逻辑“融合”,避免了传统方案中“计算-通信-计算”的串行流程。通过 kernel fusion 技术,内存访问次数减少40%,计算资源利用率显著提升。
Tips:什么是GEMM?
GEMM(General Matrix Multiplication)即通用矩阵乘法,是深度学习中最基础的计算单元,几乎所有模型(如CNN的卷积、Transformer的注意力机制)都依赖大量GEMM操作。多GPU GEMM的效率直接决定了模型训练的整体速度。
2. 无缝兼容PyTorch:让高效计算“开箱即用”
2.1 无需重构代码:从PyTorch到ThunderKittens的平滑迁移
对开发者而言,ThunderKittens最直观的优势在于与PyTorch生态的完全兼容。用户无需修改现有模型代码,仅需通过简单配置即可启用——例如,在使用torchrun启动分布式训练时,添加--backend thunderkittens参数即可切换内核。这种“零成本迁移”特性,大幅降低了技术落地的门槛。
PyTorch官方博客中提到,分布式训练工具的易用性是开发者的核心诉求之一。ThunderKittens的设计理念正契合这一方向:它保留了PyTorch熟悉的编程模型,同时将底层优化对用户透明化。
2.2 开源生态与社区支持:从代码到案例的全链路资源
ThunderKittens已在GitHub开源,仓库包含详细文档、性能测试脚本和示例代码。社区讨论中,已有开发者分享实际应用案例:某团队在训练70亿参数LLM时,使用ThunderKittens后单轮迭代时间从12分钟缩短至4.5分钟,且显存占用降低15%。
支持单位Cursor AI也在其官网提到,已将ThunderKittens集成到代码编辑器工具中,开发者可通过插件快速调用优化内核,进一步简化部署流程。
3. 产学研协同:技术创新的幕后推手
3.1 HazyResearch:斯坦福背景的AI基础设施先锋
ThunderKittens的研发团队HazyResearch隶属于斯坦福大学,长期专注于AI系统效率优化。团队成员Dylan Lim和Brandon Spector在分布式计算领域发表过多篇顶会论文,其过往项目(如FlashAttention)已成为行业标准。此次ThunderKittens的发布,延续了团队“用系统创新推动AI进步”的研究方向。
3.2 Cursor AI的产业视角:从实验室到生产环境的桥梁
作为支持单位,Cursor AI不仅提供了算力资源支持,更从开发者需求出发,推动了ThunderKittens的易用性设计。其官网提到,合作初衷是“解决企业级AI训练中的效率痛点”,而开源模式则确保了技术的普惠性。这种“学术突破+产业验证”的协作模式,让ThunderKittens在发布之初就具备了落地能力。
4. 重新定义分布式计算:影响与未来展望
4.1 对比现有工具:ThunderKittens的独特定位
当前多GPU通信工具中,NCCL(NVIDIA Collective Communications Library)是行业标杆,但需依赖NVIDIA硬件;微软DeepSpeed则更侧重超大模型的内存优化。ThunderKittens的差异化在于:
- 普适性:兼容主流GPU,不绑定特定硬件;
- 轻量级:核心代码仅2万行,部署维护成本低;
- 针对性:聚焦GEMM与通信融合,在模型计算密集场景下优势显著。
根据MLCommons的讨论,ThunderKittens已被纳入部分MLPerf基准测试的参考方案,尤其在图像识别和LLM推理任务中表现突出。
4.2 未来生态:从单一工具到分布式计算标准
随着社区反馈的积累,ThunderKittens团队计划进一步扩展功能:
- 支持更多集合操作(如all-to-all通信);
- 集成PyTorch的自动混合精度(AMP);
- 开发TensorFlow兼容版本。
行业观察者预测,若其性能优势持续验证,ThunderKittens可能成为PyTorch分布式训练的默认后端之一,推动整个AI基础设施的效率升级。
评论