GPU[15]
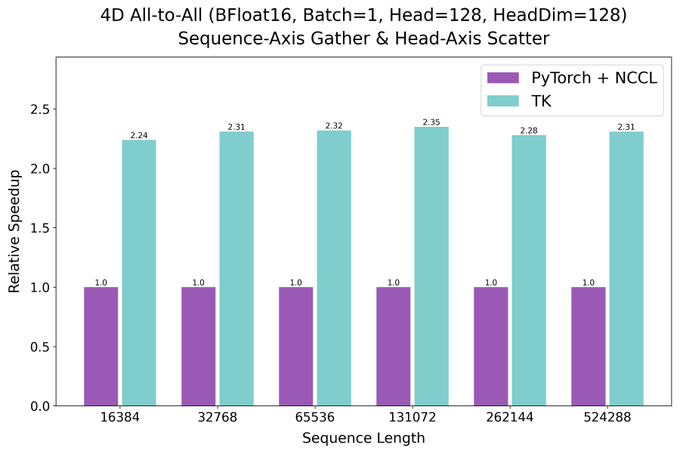
HazyResearch发布ThunderKittens多GPU内核:兼容PyTorch,性能达PyTorch+NCCL方案2.6倍
AI训练效率新突破!HazyResearch发布的ThunderKittens多GPU内核,与PyTorch无缝兼容,实测性能达传统方案2.6倍,大幅缩短ResNet-50、GPT-3等模型训练时间。其零拷贝传输与融合GEMM内核优化,降低多GPU编程门槛,已开源并获社区支持,重新定义分布式计算效率标准。


Modular 25.6发布:AI统一计算层里程碑 主流GPU性能全面突破
AI硬件碎片化难题待解,Modular 25.6版本成破局关键。作为AI统一计算层,其首次实现NVIDIA Blackwell、AMD MI355X、Apple Silicon等跨阵营GPU统一支持,MAX引擎提升数据中心算力利用率超90%,降低开发门槛,推动AI开发效率与硬件性能释放双跃升。
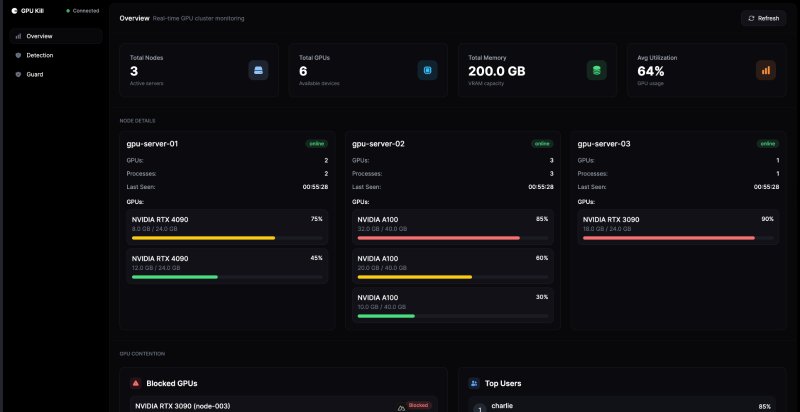
开源工具GPU Kill发布:多厂商GPU统一自动化运维解决方案
混合厂商GPU环境面临利用率低、挖矿程序侵占等管理难题,开源工具GPU Kill提供跨NVIDIA、AMD、Intel及Apple Silicon平台的统一解决方案,通过实时监控、异常检测、一键进程终止及挖矿防护,有效提升资源效率,正改变行业运维格局。
Hugging Face Transformers梯度累积修复引发多GPU训练兼容性问题
Hugging Face Transformers库PR #34191修复梯度累积机制以提升损失函数灵活性,却在多GPU环境下引发Mistral等模型序列分类任务“张量设备不匹配”错误。原因为设备同步逻辑缺失,官方已恢复同步机制并完善测试,保障分布式训练稳定性。
Mojo实现Apple Silicon GPU初步支持 Mac端AI开发迎新阵地
Mojo语言最新夜间版本实现Apple Silicon GPU初步支持,为Mac端AI开发者带来本地GPU加速新可能。此前Mac用户受硬件门槛与工具链限制,依赖云端或外接显卡,现可本地完成算法编写调试,降低开发成本、提升效率。支持M1-M4芯片,需macOS 15、Xcode 16及Metal API,已能运行矩阵运算等基础场景,未来将完善PyTorch互操作等核心功能。

Together AI主办NVIDIA Blackwell架构深度研讨会 专家解析技术突破与应用
AI算力需求激增推动底层革新,NVIDIA Blackwell架构成焦点,其5nm工艺、Transformer引擎等六大突破重塑AI基础设施。Together AI将于10月2日举办研讨会,邀NVIDIA与行业专家拆解技术内核与云服务落地路径,助力开发者抢占AI创新先机。

英伟达50亿美元入股英特尔 联手打造CPU+GPU融合芯片重塑计算格局
2024年9月,英伟达斥资50亿美元入股英特尔并达成深度战略合作,共同开发融合CPU与GPU的下一代计算芯片,聚焦数据中心与个人计算领域。依托NVLink-C2C芯粒互联技术实现硬件原生一体设计,合作推动英特尔股价暴涨22.77%,有望重塑全球计算产业格局,开启半导体“融合时代”。
Triton团队发布Gluon:专为GPU底层性能调优的新型编程语言
Triton团队发布新型GPU编程语言Gluon,作为Triton生态“性能进阶工具”,共享编译器与开发工具链,通过暴露底层硬件控制参数(如CTA分配、数据布局)填补通用编程与极致性能优化空白。开发者可灵活切换抽象层级,平衡开发效率与算力释放,适用于AI大模型核心算子、HPC等场景,被社区称为“GPU编程的罗塞塔石碑”。
月之暗面开源Checkpoint Engine:Kimi K2模型参数更新突破20秒
月之暗面(Moonshot AI)开源Checkpoint Engine技术,针对大模型强化学习训练参数同步难题,将Kimi K2模型参数更新时间从10分钟压缩至20秒,大幅提升GPU利用率与训练效率,解决大模型训练隐形瓶颈,为行业提供高效工程优化方案。
英伟达推出NVIDIA Rubin CPX GPU:首款百万级token上下文AI推理芯片,性能与内存双重突破
英伟达发布新一代AI推理GPU Rubin CPX,专为超大上下文处理与生成式视频打造,配备128GB GDDR7内存、30 PFLOPS算力(NVFP4精度优化),集成视频编解码单元,投资回报率达50倍,2026年底上市,重塑AI推理效率与应用边界。