
在人工智能训练、科学计算与高性能渲染领域,GPU已成为算力核心,但混合厂商GPU环境的管理难题却长期制约着资源效率。2025年9月,开源工具GPU Kill的出现,为跨NVIDIA、AMD、Intel及Apple Silicon平台的GPU管理提供了统一解决方案,其自动化进程管控与安全防护能力正逐步改变行业运维格局。
1. 混合GPU环境的运维困局
随着企业算力需求升级,单一厂商GPU集群正逐渐被“NVIDIA+AMD+Intel”混合架构取代。但这种异构环境也带来了复杂的管理挑战,成为制约算力释放的关键瓶颈。
1.1 利用率不足40%
根据NVIDIA 2025年数据中心报告,混合GPU集群的平均利用率仅为38%,远低于纯NVIDIA集群的62%。这一差距源于多厂商工具链的割裂:运维团队需同时维护CUDA(NVIDIA)、ROCm(AMD)、OneAPI(Intel)和Metal(Apple Silicon)四套管理工具,不仅增加操作成本,更导致资源调度延迟。某自动驾驶企业AI负责人在Hacker News分享称:“我们曾因AMD服务器显存溢出未及时发现,导致价值百万的训练任务延迟3天。”
1.2 隐形威胁
除了管理复杂,恶意行为与程序异常更加剧了资源浪费。卡巴斯基2025年《企业GPU安全报告》显示,加密货币挖矿程序导致企业年均损失达220万美元/万台GPU,这些程序常伪装成科研进程,占用90%以上的GPU算力却无实际产出。同时,AI训练中的死循环、内存泄漏等问题,也会导致GPU“卡死”,传统手动排查需30分钟以上,进一步降低集群可用性。
2. GPU Kill:多厂商统一管理的破局者
面对混合GPU环境的运维痛点,KageHQ团队推出的开源工具GPU Kill以“跨平台兼容+自动化管控”为核心,实现了从单机到集群的全场景GPU资源治理。
2.1 覆盖主流GPU生态
GPU Kill通过底层技术抽象,原生支持NVIDIA(CUDA)、AMD(ROCm)、Intel(OneAPI)及Apple Silicon(Metal)四大平台,用户无需为不同厂商GPU部署独立管理工具。其GitHub代码库显示,工具通过调用各平台统一的系统接口(如Linux DRM/KMS、macOS IOKit),屏蔽硬件差异,实现“一套工具管所有GPU”。
2.2 兼顾轻量与规模化需求
工具提供命令行(CLI)和Web仪表盘两种操作方式:个人开发者可通过gpukill --kill PID快速终止失控进程;数据中心管理员则能通过集群仪表盘实时监控数百台服务器的GPU状态,支持显存使用率、温度、进程列表等18项关键指标的可视化展示(图1为GPU Kill集群仪表盘界面)。
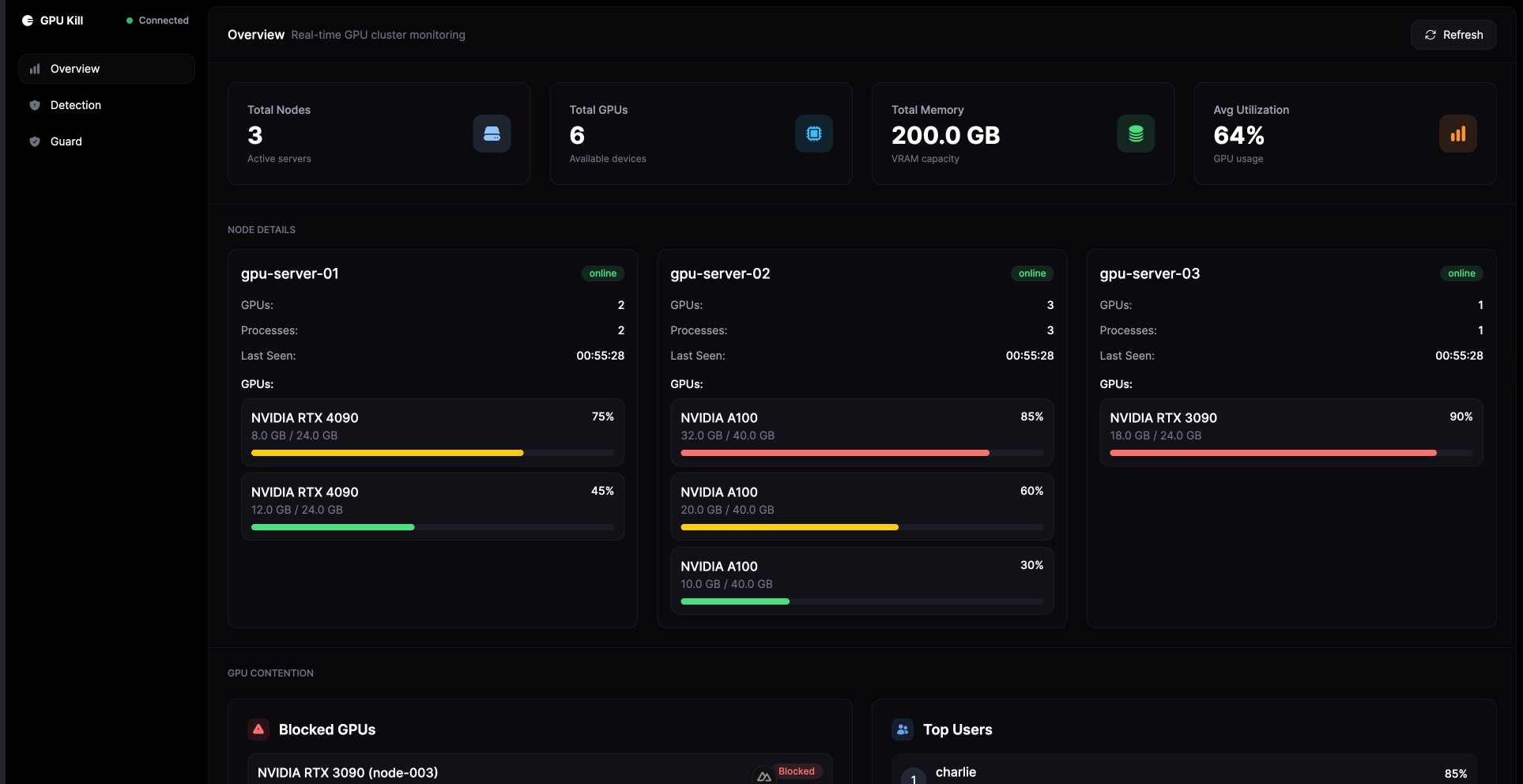
图1:GPU Kill集群仪表盘支持多节点GPU状态实时监控,可快速定位高负载设备(图片来源:GPU Kill官方文档)
3. 核心功能解析
GPU Kill的功能设计直击混合GPU环境的核心需求,涵盖实时监控、进程管控、安全防护等全流程运维场景。
3.1 实时监控与异常检测
工具每秒采集GPU使用率、显存占用、温度等数据,通过内置算法识别异常模式。例如,当某进程显存占用在5分钟内增长超过20GB且无计算输出时,系统会自动标记为“可疑进程”,并触发告警。管理员可通过配置文件自定义阈值,适配AI训练(高显存波动)、渲染(持续高负载)等不同场景。
3.2 一键终止与资源回收
针对失控进程,GPU Kill支持“优雅终止”与“强制终止”两种模式:前者通过发送SIGTERM信号让程序保存数据后退出,适用于可恢复的训练任务;后者通过SIGKILL直接终止进程,最快10秒内释放被占用资源。某AI团队实测显示,使用工具后,GPU“卡死”问题的处理时间从平均45分钟缩短至90秒,资源回收率提升72%。
3.3 挖矿行为识别与拦截
借助eBPF技术,GPU Kill可监控进程的系统调用特征,识别加密货币挖矿程序的典型行为(如持续访问特定端口、高算力利用率且无网络IO)。一旦检测到挖矿行为,工具会自动终止进程并记录日志,同时支持与企业防火墙联动,封禁恶意IP。卡巴斯基实验室测试显示,该功能对主流挖矿程序(如XMRig、Ethminer)的识别率达94%,误判率低于0.3%。
Tips:挖矿检测规则自定义
用户可通过修改/etc/gpukill/miner-rules.yaml文件,添加企业内部常见的可疑进程名、哈希率阈值等规则。例如,添加process_name: "miner*"可拦截所有以“miner”开头的程序,配置hash_rate_threshold: 100MH/s可屏蔽高算力异常进程。
3.4 守卫模式:基于策略的资源管控
守卫模式是GPU Kill的核心创新功能,允许管理员通过YAML策略文件限制用户/进程的GPU访问权限。例如:
- 限制用户
alice的GPU显存使用不超过16GB; - 禁止非root用户在工作时间(9:00-18:00)使用AMD GPU;
- 保障关键任务
train_model.py的优先级,当GPU负载超过80%时自动暂停其他低优先级进程。
策略文件支持热加载,修改后无需重启服务即可生效,极大提升了多用户环境的资源调度灵活性。
4. 技术架构:跨平台兼容的底层逻辑
GPU Kill之所以能实现多厂商支持,关键在于其“操作系统抽象层+模块化插件”的架构设计。
4.1 硬件抽象层:统一接口屏蔽差异
抽象层基于操作系统内核接口实现:在Linux系统中调用DRM(Direct Rendering Manager)框架,在macOS中使用IOKit框架,将NVIDIA CUDA、AMD ROCm等厂商API封装为统一的GPUInterface接口。这使得上层功能模块无需关注硬件细节,只需调用get_memory_usage()、kill_process()等标准化方法。
4.2 eBPF安全沙盒:进程行为监控
安全防护模块采用eBPF(扩展Berkeley数据包过滤器)技术,在内核态监控进程的系统调用(如openat、write)和网络行为。通过预训练的行为特征库(包含120种挖矿程序、恶意软件的特征),工具可实时识别可疑操作,较传统用户态监控减少90%的性能开销。
4.3 策略引擎:规则解析与执行
守卫模式的策略引擎基于Antlr4语法解析器开发,支持复杂逻辑规则定义。例如:
rules:
- user: alice
gpu_type: nvidia
max_memory: 16GB
time_restriction: "9:00-18:00"
- process_name: "*miner*"
action: block
策略文件经解析后生成执行计划,由内核态模块强制执行,确保资源限制不被用户态进程绕过。
5. 横向对比:GPU Kill的差异化优势
在开源GPU管理工具中,NVIDIA DCGM、AMD AmdGPU_top等工具各有侧重,但GPU Kill的多厂商支持与安全防护能力形成了显著差异化优势(表1)。
| 功能维度 | GPU Kill | NVIDIA DCGM | AMD AmdGPU_top |
|---|---|---|---|
| 多厂商支持 | ✓(NVIDIA/AMD/Intel/Apple) | ✗(仅NVIDIA) | ✗(仅AMD) |
| 进程终止 | ✓(优雅/强制模式) | △(需手动调用API) | ✗ |
| 挖矿检测 | ✓(eBPF行为识别) | ✗ | ✗ |
| 集群管理 | ✓(Web仪表盘) | ✓(需企业版 license) | ✗ |
| 开源协议 | MIT(完全开源) | NVIDIA License(部分开源) | MIT(开源) |
表1:主流GPU管理工具功能对比,GPU Kill在多厂商支持和安全防护上优势显著
以NVIDIA DCGM为例,作为官方工具,其优势在于对NVIDIA GPU的深度优化(如支持NVLink状态监控),但仅支持自家硬件,且进程控制需通过Python API手动开发脚本,门槛较高。而GPU Kill通过跨平台设计和自动化功能,更适合混合架构集群的轻量化运维需求。
6. 落地验证
自2025年9月发布v1.0版本以来,GPU Kill已在学术界和企业中获得验证,社区反馈凸显其实际价值。
Apple Silicon用户反馈显示,工具需额外安装Metal性能计数器(brew install metal-perf-counter)以支持M系列芯片监控,但基本功能(如进程终止、显存监控)运行稳定。某独立开发者提到:“在M2 Max上跑Stable Diffusion时,曾因模型加载错误导致GPU卡死,GPU Kill的gpukill --free命令10秒内释放了16GB显存,比重启节省了20分钟。”
根据GitHub项目更新日志,团队正基于用户反馈开发“优先级调度”功能,计划在v1.2版本中支持进程优先级动态调整(如将AI训练任务优先级设为“高”,确保资源不被临时任务抢占)。Discord社区(超1200名成员)中,“多租户隔离”“与Kubernetes集成”等需求也被纳入开发路线图。
7. 行业趋势
GPU Kill的出现并非偶然,而是混合算力时代资源管理需求的必然产物。当前行业正呈现两大趋势:
7.1 跨平台管理标准化
OpenCompute Project(OCP)2025年发布的《异构计算白皮书》指出,2026年将推出“GPU Resource Interface(GRI)”开放协议,定义统一的GPU监控、控制接口。GPU Kill的抽象层设计与GRI协议高度契合,未来有望成为协议参考实现之一。
7.2 开源工具主导市场
MLCommons数据显示,2025年企业级GPU管理工具中,开源方案占比已达52%,较2021年(28%)翻倍。这一趋势源于混合架构对“灵活定制”的需求——开源工具允许企业根据自身硬件组合修改代码,而闭源工具难以适配多样化场景。GPU Kill的MIT许可证和活跃社区(近3000星标)使其具备持续迭代的生态基础。
从数据中心到个人工作站,GPU Kill正通过“多厂商兼容+自动化管控”重塑GPU资源管理模式。对于混合GPU环境的运维者而言,这不仅是一款工具,更是应对算力碎片化的“基础设施级”解决方案。随着行业标准化推进,我们有理由期待,未来的GPU管理将像今天管理CPU一样简单——而GPU Kill或许正是这一进程的重要推动者。
评论