算力[29]
Google Cloud推出Vertex AI Training:托管Slurm赋能企业级AI训练,挑战CoreWeave与AWS
企业级AI模型训练面临算力紧张、作业调度复杂及故障恢复难等挑战。Google Cloud近期推出Vertex AI Training服务,以托管Slurm环境为核心,集成自动故障恢复与检查点管理,提供端到端训练解决方案,简化资源分配与任务监控,挑战AWS、CoreWeave等对手,助力企业降低定制化门槛,提升训练效率。

苹果休斯顿工厂提前出货AI服务器 支撑Apple Intelligence及私有云核心算力
苹果AI赛道布局提速,其美国休斯顿新工厂已提前启动AI服务器出货,较原计划大幅提前。依托美国CHIPS法案及德州补贴,叠加与台积电合作实现供应链周期压缩,该工厂为Apple Intelligence平台及私有云计算注入核心算力。其端云协同架构通过定向传输技术实现数据隐私与算力平衡,或将为行业树立算力、隐私、安全三位一体新标准。
OpenAI Stargate项目投资500亿美元:350亿专攻AI芯片,打造111吉瓦超级算力中心
OpenAI代号“Stargate”的超级数据中心项目,计划投资500亿美元打造1GW全球顶级算力,其中350亿专项用于AI芯片采购,占比达70%,凸显AI基础设施“烧钱”本质。该项目推动全球算力竞赛升级,2030年全球AI基建投资或破1.1万亿美元,算力成科技竞争力核心,行业正迎来芯片采购与自研的战略分化。
Gensyn发布多项前沿研究 推动机器智能网络迈向开放未来
AI行业面临算力垄断与可信协作难题,Gensyn构建去中心化机器智能协议,融合区块链与分布式机器学习技术,通过概率性审计机制与双代币模型解决验证效率与安全痛点,激活全球闲置算力,已在医疗联合建模、制造业多智能体协同等场景落地,推动AI技术开放普惠发展。

OpenAI与英伟达洽谈AI芯片租赁合作 探索算力资源新获取模式
AI行业算力获取方式正迎变革,OpenAI与英伟达正探讨芯片租赁合作,拟告别传统采购转向按需租赁。此举旨在缓解算力需求激增下的成本压力——传统模式硬件投入高、资源利用率不足60%,而租赁可将重资本支出转为轻运营支出,提升资源利用率至85%以上,还能降低中小企业AI研发门槛,推动算力服务化与行业民主化落地。

Modular 25.6发布:AI统一计算层里程碑 主流GPU性能全面突破
AI硬件碎片化难题待解,Modular 25.6版本成破局关键。作为AI统一计算层,其首次实现NVIDIA Blackwell、AMD MI355X、Apple Silicon等跨阵营GPU统一支持,MAX引擎提升数据中心算力利用率超90%,降低开发门槛,推动AI开发效率与硬件性能释放双跃升。

OpenAI、Oracle与软银加速Stargate计划:新增五大AI数据中心,投资超4000亿美元
OpenAI、Oracle与软银联合加码Stargate AI基础设施计划,新增五大数据中心,总规划算力近7吉瓦,未来三年投资超4000亿美元,提前实现2025年底目标,标志全球AI算力竞赛进入“吉瓦级”新阶段,为下一代算力革命注入强劲动力。

OpenAI与NVIDIA达成百亿级战略合作 共建10GW AI基础设施
2025年9月22日,OpenAI与NVIDIA宣布战略合作,计划共建10吉瓦(GW)算力超级系统,NVIDIA分阶段投资1000亿美元,系行业最大规模算力部署,标志AI基础设施竞赛进入ExaScale级新阶段。双方十年技术协同,从DGX-1到ChatGPT算力支撑,首期1GW 2026年落地Vera Rubin平台,基于Blackwell Ultra GPU与液冷集群,推动超级智能时代跃迁。
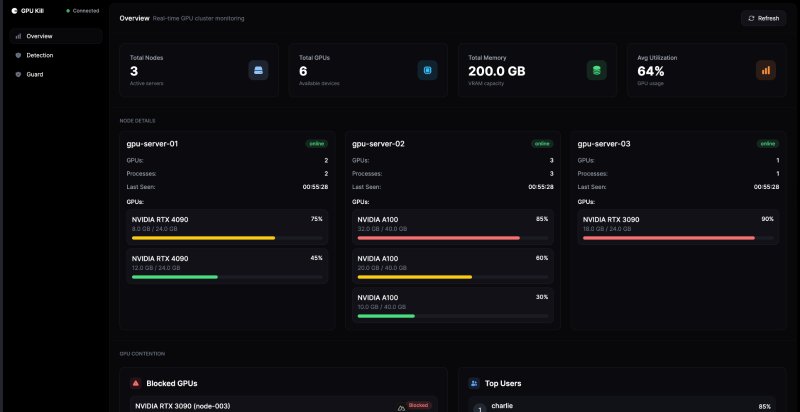
开源工具GPU Kill发布:多厂商GPU统一自动化运维解决方案
混合厂商GPU环境面临利用率低、挖矿程序侵占等管理难题,开源工具GPU Kill提供跨NVIDIA、AMD、Intel及Apple Silicon平台的统一解决方案,通过实时监控、异常检测、一键进程终止及挖矿防护,有效提升资源效率,正改变行业运维格局。
阿联酋数据中心巨头Khazna:70%市占率与技术创新 重塑全球AI基础设施版图
阿联酋数据中心巨头Khazna掌控本国70%市场份额,为谷歌、亚马逊等提供AI算力支撑。其沙漠液冷技术实现PUE 1.08全球领先,适配高密度GPU集群,依托数据主权战略与全球化布局,成中东数字经济跨越式发展标杆,挑战西方数字基建主导地位。