
最近,AI领域又迎来一个重磅消息——阿里巴巴通义实验室正式发布了通义DeepResearch,这款被称为“全球首个完全开源Web Agent”的产品,以“小参数撬动高性能”的特点迅速引发行业关注。不同于以往AI模型追求“参数竞赛”的路径,通义DeepResearch用300亿总参数(实际推理仅激活30亿)就实现了与OpenAI同类产品相当的能力,还把代码和权重完全开源。这不仅是一次技术突破,更可能为Web Agent的普及和应用打开全新空间。
1. 通义DeepResearch:重新定义Web Agent的“小而美”
提到Web Agent,大家可能会想到那些能模拟人类操作浏览器、自动完成信息检索、任务执行的AI工具。但过去这类工具要么是闭源的“黑盒”(比如OpenAI的浏览器插件),要么是性能有限的开源项目。通义DeepResearch的出现,恰恰打破了这一局面。
根据通义实验室官方信息,这款Web Agent于2024年5月29日正式发布,核心亮点可以概括为三个“关键词”:
- 高效参数:总参数300亿,但采用创新架构,每次推理仅激活30亿参数,兼顾性能与效率;
- 开源开放:模型权重和代码已在魔搭社区(ModelScope)、Hugging Face等平台上线,且允许商用,开发者可直接下载微调;
- 性能对标:在Web Agent核心能力测试中,成绩比肩行业顶级水平,实现“小模型办大事”。
为什么“激活参数”这个点如此重要?要知道,传统大模型的参数是“全量激活”的,比如1000亿参数模型推理时,所有参数都要参与计算,这意味着更高的硬件成本和延迟。而通义DeepResearch的“30亿激活”设计,相当于给模型装了一个“智能开关”,只调用当前任务最需要的“算力”,既保证了能力,又降低了使用门槛。
2. 揭秘“300亿总参,30亿激活”:MoE架构如何实现效率飞跃
看到“总参数300亿,激活30亿”,很多人可能会疑惑:这是不是“阉割版”模型?恰恰相反,这背后藏着AI架构设计的“大智慧”——混合专家(Mixture-of-Experts, MoE)架构。
简单来说,MoE架构就像一个“AI团队”:模型总参数由多个“专家子网络”(比如10个各30亿参数的专家)组成,每个专家擅长处理不同类型的任务(比如有的擅长信息检索,有的擅长逻辑推理)。当模型接收任务时,一个“门控网络”会像“项目经理”一样,根据任务类型选择最相关的1-2个专家参与计算,其他专家则处于“休眠”状态。这样一来,总参数虽然有300亿(10个专家×30亿),但每次推理仅激活30亿(1个专家),效率自然大幅提升。
Tips:为什么MoE架构是效率革命的关键?
传统大模型是“全能选手”,用一套参数应对所有任务,导致参数利用率低。而MoE架构通过“分工协作”,让每个参数更专注于擅长的领域,既提升了能力上限(总参数规模大),又降低了推理成本(激活参数少)。目前,Mistral 8x7B、Google GLaM等知名模型都采用了类似思路,通义DeepResearch则将其成功应用到Web Agent这一复杂场景。
3. 实测数据说话:三大权威基准验证OpenAI级性能
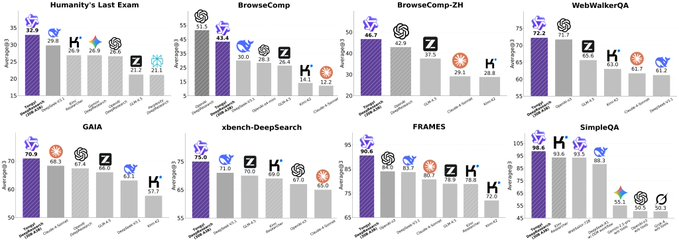
光说架构创新不够,性能才是硬道理。通义DeepResearch在Humanity’s Last Exam(HLE)、BrowseComp、xbench-DeepSearch三大权威基准测试中交出了亮眼答卷,直接对标行业顶级水平。
Humanity’s Last Exam(HLE):综合推理能力的“试金石”
HLE是目前AI领域最难的综合测试之一,涵盖数学、科学、人文等复杂问题,专门考察模型的逻辑推理和常识理解能力。通义DeepResearch在这里拿到了32.9分——要知道,这个分数已经接近GPT-4等闭源大模型的表现,远超许多开源竞品,证明它不仅“会操作浏览器”,更具备深度思考能力。
BrowseComp:Web Agent的“实战考场”
作为Web Agent的核心能力,“模拟人类操作浏览器完成任务”(比如“找到某商品并加入购物车”“查询天气并生成周报”)是最关键的考核。BrowseComp基准通过模拟上百种真实网页场景,测试模型的指令理解、页面交互和任务规划能力。通义DeepResearch以45.3分的成绩位居当前开源模型前列,这个分数意味着它已经能处理大部分日常网页任务,实用性大幅提升。
xbench-DeepSearch:深度信息检索的“冠军级表现”
在需要“从海量网页中精准挖掘信息并整合”的xbench-DeepSearch测试中,通义DeepResearch更是拿下75.0分的高分。这说明它不仅能“浏览网页”,还能像人类研究员一样,理解复杂查询(比如“分析2024年新能源汽车销量变化的三大原因”),从多个来源提取关键信息并形成结论,核心能力直指专业级信息处理。
| 测试名称 | 通义DeepResearch成绩 | 能力定位 | 行业意义 |
|---|---|---|---|
| Humanity’s Last Exam | 32.9分 | 综合推理与常识理解 | 接近闭源大模型水平,开源领域领先 |
| BrowseComp | 45.3分 | 网页交互与任务执行 | 开源Web Agent第一梯队性能 |
| xbench-DeepSearch | 75.0分 | 深度信息检索与整合 | 专业级信息处理能力,实用性突出 |
此外,通义DeepResearch还参与了包括 WebWalkerQA、GAIA、wseComp、vseComp-ZH 在内的多个专项评测,覆盖问答、推理、中文网页理解等能力维度,进一步验证其作为通用Web Agent的综合实力。
4. 完全开源+可商用
除了性能,通义DeepResearch的“完全开源”策略同样值得关注。目前,模型权重和代码已在魔搭社区(ModelScope) 和Hugging Face两大平台上线,开发者不仅可以免费下载使用,还能基于它进行二次开发,甚至用于商业场景——这种“开源到底”的态度,在高性能Web Agent领域极为罕见。
要知道,在此之前,具备类似能力的Web Agent(如OpenAI的Browse with GPT-4)大多是闭源API服务,企业和开发者只能“调用”而无法“掌控”,成本高且定制化受限。通义DeepResearch的开源,相当于把“顶级Web Agent的源代码”递给了所有人:
- 对开发者:可以直接基于开源代码研究Web Agent的核心逻辑(如网页交互策略、信息检索算法),快速上手开发自己的应用;
- 对企业:无需依赖第三方API,可本地化部署并根据业务需求微调模型(比如电商平台定制“智能导购Agent”,教育机构开发“自动资料整理Agent”),数据安全和成本可控性大幅提升;
- 对行业:开源意味着更多人能参与技术迭代,加速Web Agent在垂直领域的落地(如医疗、法律、科研),推动整个生态从“概念验证”走向“规模化应用”。
5. 技术突破到产业落地的启示
通义DeepResearch的发布,不止是“多了一个开源模型”,更标志着Web Agent领域从“闭源垄断”向“开源普惠”的转折。它的意义可以从三个层面来看:
对技术路径:参数效率比“堆参数”更重要
过去,AI模型似乎陷入了“参数竞赛”的怪圈,仿佛“参数越大能力越强”。但通义DeepResearch证明,通过架构创新(如MoE)和任务优化,小参数模型也能实现高性能。这种“重效率而非规模”的思路,可能会成为未来AI模型发展的主流方向。
对开源生态:填补高性能Web Agent的空白
在开源社区,Web Agent项目并不少,但大多停留在“玩具级”能力(如只能完成简单点击)。通义DeepResearch以“OpenAI级性能+完全开源”的组合,直接填补了“顶级开源Web Agent”的空白,为开发者提供了一个可信赖的技术底座。
对产业落地:从“实验室”走向“千行百业”
Web Agent的终极价值是“解放人类双手”——让AI自动处理网页操作、信息检索、流程化任务。随着通义DeepResearch的开源,我们可能很快看到:电商平台用它做智能客服,科研机构用它整理文献,甚至普通人用它自动生成旅行攻略……技术的民主化,正在加速AI从“实验室”走向“千行百业”。
通义DeepResearch的出现,让我们看到了AI发展的另一种可能:不追求“参数霸权”,而是通过架构创新和开源共享,让技术更高效、更普惠。对于开发者来说,这是一个可以直接上手的“顶级工具”;对于行业来说,这是一次从“技术突破”到“产业变革”的契机。相信随着更多人参与其中,Web Agent的未来会更加值得期待。
评论