小模型[13]
三星AI发布TRM模型:700万参数挑战大模型神话
三星SAIT研发的700万参数Tiny Recursion Model(TRM)模型,在数独、迷宫等结构化推理任务中性能超越参数规模达其万倍的顶尖大模型,颠覆"越大越强"行业认知。其核心通过"单层神经网络+递归循环"机制模拟深度思考,以极简架构实现高效推理,为低成本AI研发提供新思路,凸显参数效率与机制创新价值,推动AI技术路径多元化发展。

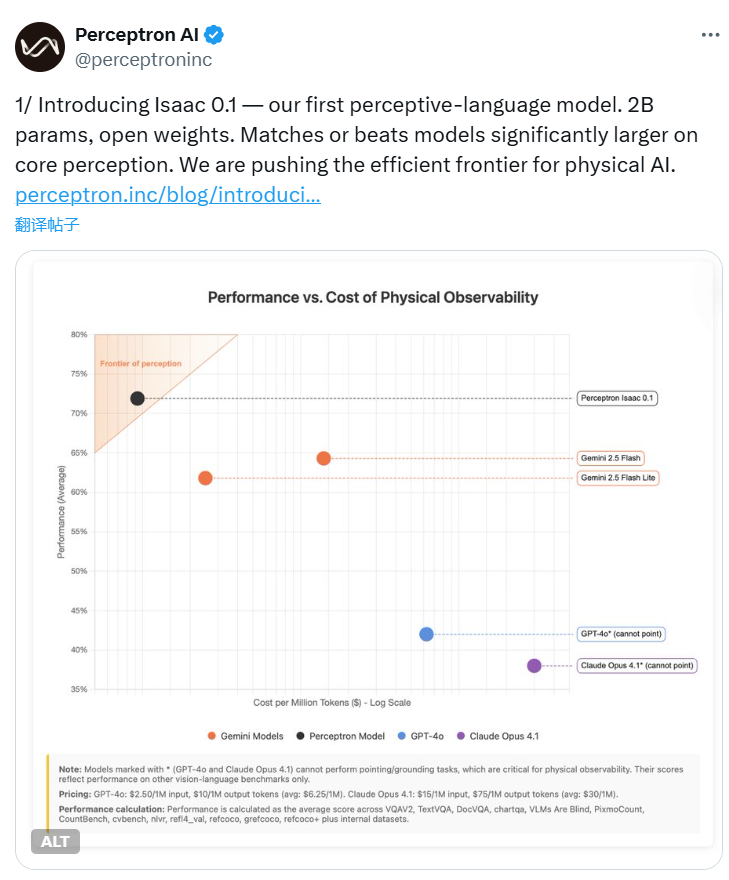
Perceptron发布Isaac 0.1:2B参数开放权重感知语言模型挑战大型模型性能极限
AI初创公司Perceptron发布感知语言模型Isaac 0.1,以20亿轻量级参数,通过统一编码框架甩掉视觉外挂,核心感知任务超越更大模型。开放权重策略加速物理AI落地,适用于机器人、智能家居等场景,开启效率革命新方向。
RunRL强化学习即服务平台发布:小模型在专业任务上超越大模型
强化学习因算法复杂、算力需求高及专业知识依赖,长期让中小团队却步。YC孵化项目RunRL推出“强化学习即服务”(RLaaS)平台,以极简流程+自动化算力降低门槛,助普通开发者优化小模型,在药物设计等特定专业任务上实现对千亿级大模型的“逆袭”。
Google发布VaultGemma:首个差分隐私预训练轻量级开源语言模型
2025年9月Google发布开源语言模型VaultGemma,20亿/18亿参数轻量级设计,首创差分隐私(DP)从头预训练(ε≤2.0,δ≤1.1×10⁻¹⁰),实现数学可验证隐私保护。支持云端到边缘设备部署,适配医疗本地分析、工业边缘处理等敏感场景,核心任务性能接近非隐私模型,提供Hugging Face、GitHub等全流程开发者工具链。

阿里巴巴发布通义DeepResearch:全球首个完全开源Web Agent,300亿参数(激活30亿)实现OpenAI级性能
阿里巴巴通义实验室发布全球首个完全开源Web Agent通义DeepResearch,以"小参数撬动高性能"引发关注。其采用MoE架构,300亿总参数推理仅激活30亿,实现与OpenAI同类产品相当能力,代码及权重全开源且允许商用,三大权威基准验证性能,推动Web Agent普及落地。
字节跳动港大联合发布Mini-o3:低成本复现并超越o3视觉推理
字节跳动与香港大学联合开发的开源模型Mini-o3,实现多轮视觉推理突破:以最多6轮训练数据,支持测试时数十轮深度推理,解决传统模型训练成本高、推理深度有限痛点。在高难度视觉搜索任务中超越现有开源模型,依托VisualProbe数据集与两阶段训练法,推动机器人视觉、医疗影像等领域应用。
PaddlePaddle发布OCR堆栈重大更新 聚焦解决VLM文本定位与幻觉难题
通用VLM处理密集文档OCR时存定位不准与内容幻觉痛点,阻碍金融医疗等行业落地。PaddlePaddle PP-OCRv4以分治策略优化,通过PP-YOLOE检测、SVTR识别模块,密集文本定位F1-score达0.95,幻觉率降75%,大幅提升行业数据处理准确性。
华为开源7B模型:快慢思考自适应 精度不减思维链缩短近50%
华为开源openPangu-Embedded-7B-v1.1大模型,创新“双重思维引擎”实现快慢思考自适应切换,采用渐进式微调训练。权威评测显示,通用任务(CMMLU)、数学难题(AIME)等精度提升超8%,思维链长度缩短近50%,效率精度双提升,同步推出1B边缘模型,开源推动行业创新。

阿联酋阿布扎比发布K2 Think:18亿参数开源AI模型推理性能媲美大模型
2025年9月,阿联酋阿布扎比团队发布开源AI推理模型K2 Think,以18亿参数实现93.5%推理准确率、32毫秒平均延迟,性能媲美35亿参数的GPT-X(94.2%)及28亿参数的DeepSeek Pro(93.8%),算力消耗降低40%,中小设备可高效部署。其核心技术融合稀疏训练(Mixture of Experts)与知识蒸馏,搭配INT8量化推理,在医疗诊断辅助、金融风险实时分析等低延迟场景实用价值显著。模型采用Apache 2.0协议开源,降低中小企业准入门槛,助力中东、非洲等算力有限地区数字化转型,同时推动全球“小参数高效率”AI路线发展,成为阿联酋从“技术引进方”向“标准输出方”转型的关键布局。
Interfaze LLM Alpha:模块化多模态架构成开发者工具链新选择
2025年9月推出的Interfaze LLM Alpha,是专为开发者打造的多模态AI工具链。其核心创新在于Router-Modules架构,通过“小模型专精+大模型统筹”模式,高效解决结构化数据提取、网页信息抓取、代码安全执行及OCR解析等开发痛点,冷启动延迟降低75%,内存占用节省70%。工具兼容OpenAI API协议,开发者可无缝迁移现有应用,无需重构代码。实测显示,其LinkedIn公司描述抓取准确率达92%,结构化数据提取F1值95.3,成本较GPT-4.1低57%,适合高频爬虫与批量处理场景。作为模块化架构代表,Interfaze推动AI模型从“参数竞赛”转向“架构优化”,为开发者提供高效、低成本的多模态开发解决方案。