微调[1]
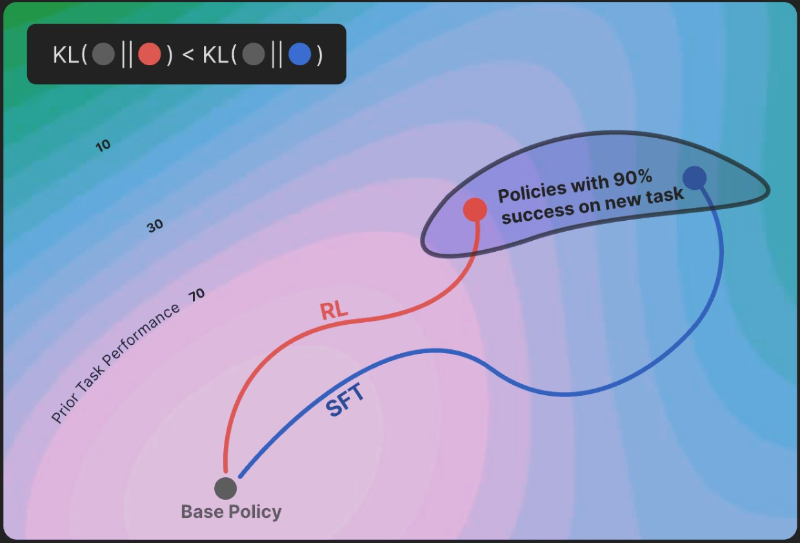
强化学习(RL)缓解大模型灾难性遗忘:OpenAI、Meta等验证保守更新机制
大模型持续学习面临“灾难性遗忘”难题,即学习新任务时易丢失旧知识,传统监督微调(SFT)因参数更新偏向新任务,常导致旧任务保留率不足60%。而强化学习(RL)通过KL散度最小化机制实现“保守更新”,让新模型分布贴近原始知识分布,有效缓解遗忘。实验显示,RL在新任务准确率与SFT持平(约92%)的情况下,旧任务保留率提升20%+,如数学推理与代码生成任务保留率达81.7%。目前OpenAI、Meta、Google等企业已将RL融入微调流程,如RLHF中的KL惩罚项、“螺旋课程微调”等。尽管存在多任务冲突、训练成本等挑战,RL仍为构建“终身学习型AI”提供关键路径,推动大模型从“一次性学习”向持续进化跨越。
