
1. 多模态大模型的“成长烦恼”:灾难性遗忘问题
当我们谈论AI大模型时,往往惊叹于它们在图像识别、自然语言处理等任务上的卓越表现。但在现实应用中,这些“智能体”却面临一个棘手的“成长烦恼”——灾难性遗忘。简单来说,当大模型学习新任务或适应新环境时,常常会显著遗忘之前掌握的知识。例如,一个训练好的电商客服AI,在学习处理家电售后问题后,可能会忘记如何解答服装尺码咨询;医疗影像分析模型在新增皮肤病识别能力后,对肺癌影像的诊断准确率可能大幅下降。
这种现象的根源在于大模型参数的高度关联性:新任务的训练会覆盖旧任务相关的参数权重,导致知识“断崖式”丢失。随着多模态大模型(如LLaVA、Gemini)在智能驾驶、机器人交互等动态场景中的普及,如何让模型在持续学习中兼顾“学新”与“温故”,成为工业界和学术界的核心挑战。近期,中国科学院自动化研究所联合中国科学院香港院AI中心的团队,通过系统性研究为这一问题提供了突破性解决方案。
2. 系统性研究框架:从综述到基准再到方法
面对多模态大模型的持续学习难题,研究团队并未局限于单点技术改进,而是构建了一套“理论-工具-实践”三位一体的研究体系。这一系列成果已发表于CVPR、ICLR、ACL等国际顶会,并开源了完整的代码与数据,为行业提供了可复用的技术范式。
2.1 全景式综述:厘清持续学习的技术脉络
团队首先发布了综述论文《Continual Learning for Generative AI: From LLMs to MLLMs and Beyond》,系统梳理了生成式AI持续学习的研究进展。该综述覆盖四大模型类型:
- 大语言模型(LLMs):如GPT系列在文本生成任务中的持续学习策略;
- 多模态大语言模型(MLLMs):如LLaVA、Flamingo等在跨模态任务中的知识保留方法;
- 视觉语言动作模型(VLA):如具身智能体在交互任务中的动态适应;
- 扩散模型:如图像生成模型在风格迁移中的持续优化。
综述还归纳了三大核心技术路线:架构扩展(调整模型结构增强适应性)、正则化策略(通过正则项抑制参数剧烈变化)、回放机制(引入旧数据回放巩固记忆),并提出了“整体性能-遗忘程度-泛化能力”三维评估指标。相关内容已整理至开源项目主页Awesome-Continual-Learning-in-Generative-Models,成为领域研究者的重要参考。

图1:生成式AI持续学习示意图,展示模型在动态任务流中的知识保留与更新过程
2.2 从“无标可依”到“标准统一”:创新基准的提出
解决问题的前提是精准定义问题。传统持续学习研究多依赖单模态分类任务(如图像分类),且评测数据集常与模型预训练数据重叠,导致评估结果“虚高”。为此,团队针对性提出两大创新基准:面向通用场景的UCIT和面向分布式场景的FCIT,填补了多模态持续学习评测体系的空白。
3. UCIT基准:解决评估失真的“试金石”
UCIT(Unified Continual Instruction Tuning Benchmark) 的核心目标是消除“数据泄露”对评估的干扰,确保模型真实能力的准确衡量。其设计蕴含三大关键创新:
3.1 Zero-shot筛选:构建“纯净”的任务数据集
团队从科学图解、历史事件、古籍修复等12个预训练未覆盖的领域中筛选数据,通过严格的zero-shot机制确保指令数据与模型预训练语料无重叠。例如,在“科学图解”任务中,数据集包含量子力学示意图的问答指令,而这些内容未出现在LLaVA等模型的预训练数据中。为验证独立性,研究采用CLIP-ViT特征相似度计算,将阈值设为<0.25,确保新任务数据与旧知识“无交集”。
3.2 多粒度评估:不止“会不会”,更看“忘多少”
UCIT涵盖视觉问答(VQA)、图像描述、图表理解等6类多模态任务,不仅评估模型在新任务上的准确率,还创新性引入“性能衰减率”指标:
[ \text{衰减率} = \frac{\text{旧任务初始准确率} - \text{新任务学习后旧任务准确率}}{\text{旧任务初始准确率}} ]
通过该指标可量化模型遗忘程度,例如某模型在图像描述任务上初始准确率为85%,学习新任务后降至70%,则衰减率为17.6%。
3.3 开源生态:让评估“有章可循”
UCIT数据集已开源至Hugging Face(HaiyangGuo/UCIT),包含详细的任务说明、数据划分及评估脚本。研究者可直接基于此基准测试自家方法,避免重复造轮子。
4. HiDe-LLaVA:层次化解耦的高效学习方案
有了可靠的“试金石”,团队进一步提出HiDe-LLaVA方法,通过层次化解耦策略实现“高效学新,少忘旧知”。其核心灵感源于模型层间特性的发现:通过CKA(Centered Kernel Alignment)相似性分析,团队观察到多模态大模型的顶层参数具有任务特异性(如处理VQA和图像描述时激活模式差异显著),而中低层参数则保留跨任务通用知识。
4.1 分层优化:精准“动刀”2.4%参数
HiDe-LLaVA的创新在于“按需调整”:
- 顶层(任务特异性层):引入多模态锚点驱动的动态专家模块。例如,为VQA任务分配视觉特征主导的专家子网络,为图像描述任务分配语言生成主导的专家子网络,通过门控机制动态选择激活。
- 中低层(通用知识层):采用参数融合策略,冻结大部分参数,仅通过轻量级适配器融合新旧任务知识,避免通用特征被覆盖。
这种设计使模型仅需调整2.4%的参数量(基于LLaVA-1.5的13B版本,约316M参数可调节),大幅降低计算成本。
4.2 实验验证:遗忘率仅3.8%,性能全面领先
在UCIT基准上的测试显示,HiDe-LLaVA表现突出:
- 遗忘控制:旧任务平均衰减率仅3.8%,显著低于传统Adapter方法(18.7%)和全参数微调(27.3%);
- 新任务学习:在科学图解VQA任务上准确率达74.3%,较基线方法提升9.2%;
- 跨模态能力:视觉-文本特征相似性矩阵显示,顶层专家模块使模态特异性学习效率提升27%。
相关代码已开源至GitHub仓库,包含模型权重、训练脚本及复现指南。

图2:HiDe-LLaVA模型框架示意图,展示顶层动态专家模块与中低层参数融合策略
5. FCIT基准:联邦场景下的持续学习新范式
在医疗、金融等敏感领域,数据难以集中训练,联邦学习(Federated Learning)成为刚需。但现有联邦方案在动态任务场景下,常陷入“学新任务就忘旧知识”的困境。为此,团队提出FCIT(Federated Continual Instruction Tuning) 基准,首次构建联邦环境下的多模态持续学习评测体系。
5.1 贴近现实的场景设定
FCIT支持两种典型联邦场景:
- 同质环境:所有客户端(如医院分院)学习相同类型任务(如CT影像诊断),但数据分布异构(不同医院病例差异);
- 异质环境:客户端学习不同任务(如A医院学CT诊断,B医院学X光分析),需模型在本地更新时保留全局知识。
5.2 四大核心特性保障评测科学性
- 异构硬件模拟:包含移动端(如手机)、边缘设备(如边缘服务器)等4类硬件配置,设置延迟阈值(如移动端200ms),测试模型在资源受限下的性能;
- 隐私保护验证:集成动态梯度掩码技术,确保客户端上传梯度中不泄露原始数据,通过“相似度分析误差<0.03”验证隐私安全性;
- 高价值任务测试集:包含医疗影像标注、金融报表分析等需长期记忆的任务,模拟现实中“不能忘”的关键知识;
- 开源工具链:数据集(MLLM-CL/FCIT)与评测代码(GitHub)开源,支持研究者快速复现。
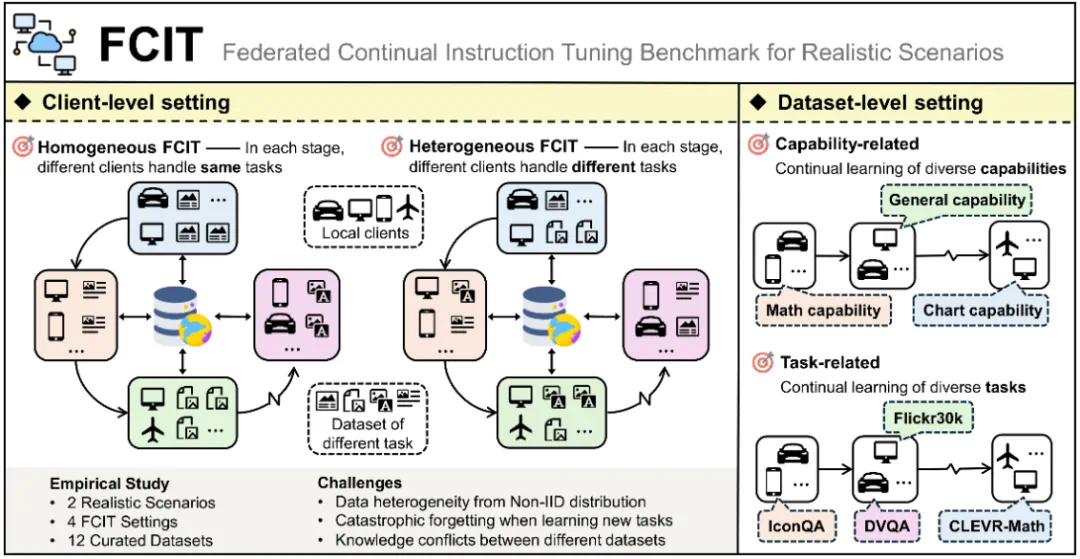
图3:FCIT设定示意图,展示异构客户端在联邦持续学习中的任务分配与知识交互
6. 持续学习的未来:从技术突破到行业价值
中科院自动化所团队的系列成果,不仅在学术上推动了持续学习理论的发展,更在工业界具有明确的应用价值:
- 降低部署成本:HiDe-LLaVA的参数效率使其可在消费级硬件上部署,企业无需更换设备即可实现模型迭代;
- 保障关键任务稳定:FCIT基准为医疗、自动驾驶等领域提供了安全可靠的持续学习方案,避免因更新导致核心功能退化;
- 加速行业创新:开源的综述、基准与代码(GitHub仓库已获170+星标)降低了研究门槛,推动全行业共同探索“终身学习”AI。
未来,随着多模态数据规模增长和应用场景复杂化,持续学习将向高效机制(如动态路由、神经可塑性)、跨模态扩展(融合语音、传感器数据)、强化学习范式(通过奖励机制平衡学新与温故)等方向深化。正如团队在综述中展望:“让AI像人类一样,在成长中积累经验,而非每次从零开始。”
参考链接
- Continual Learning for Generative AI: From LLMs to MLLMs and Beyond
- Awesome-Continual-Learning-in-Generative-Models
- HiDe-LLaVA: Hierarchical Decoupling for Continual Instruction Tuning of Multimodal Large Language Model
- HiDe-LLaVA代码库
- UCIT数据集
- Federated Continual Instruction Tuning
- FCIT代码库
- FCIT数据集
- 机器之心
评论