
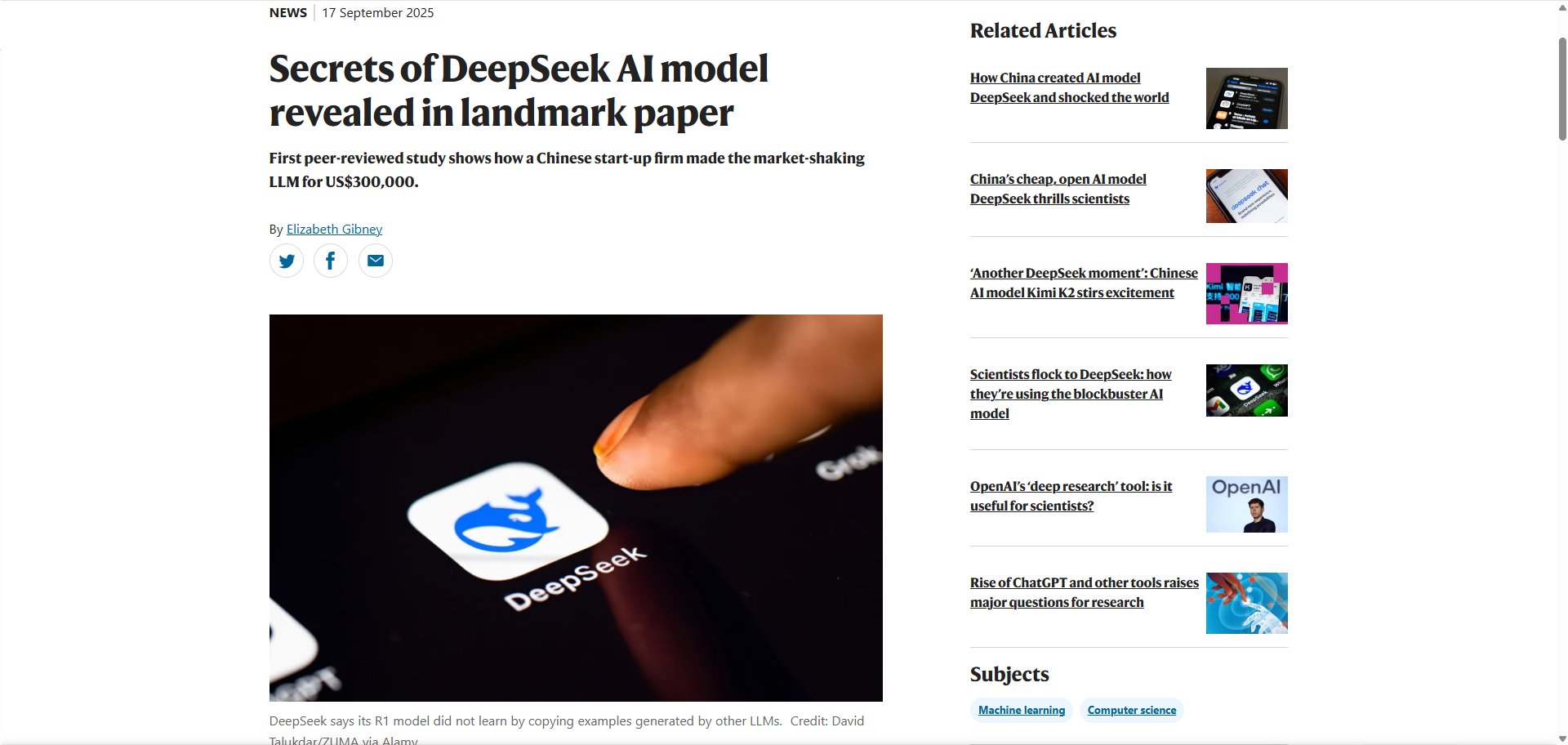
DeepSeek R1近日登上国际顶级期刊《Nature》封面,成为首个获此殊荣的中国大模型。这一突破不仅标志着中国AI技术得到全球顶尖学术舞台的认可,更以660B参数模型仅208万元训练成本的“逆天性价比”,颠覆了业界对大模型研发的固有认知。从技术路径到开源生态,DeepSeek R1正在重塑全球AI竞争格局。
1. 中国大模型首次问鼎Nature封面:全球AI领域的中国印记
《Nature》封面历来是全球科技突破的“风向标”,此前登上封面的AI项目多为DeepMind的AlphaGo(围棋革命)、AlphaFold(蛋白质结构预测)等里程碑式成果。DeepSeek R1此次入选,直接将中国大模型推向了国际AI研究的第一梯队。
论文通讯作者、DeepSeek创始人梁文锋在接受《Nature》采访时表示:“这不是偶然的突破,而是中国AI从‘技术跟随’转向‘理论引领’的证明。”Hugging Face机器学习工程师Lewis Tunstall评价其为“首个通过严格同行评审的大型语言模型”,其方法论已被MIT、斯坦福等机构的后续研究引用。俄亥俄州立大学AI研究员Huan Sun则指出,R1提出的强化学习框架“几乎重构了大语言模型推理能力优化的研究路径”。
(图:DeepSeek R1登上《Nature》封面,封面以蓝色神经网络背景融合数学公式,凸显“推理能力跃升”主题,来源:Nature官网)
2. 660B参数模型仅208万训练成本:颠覆行业认知的“成本革命”
在大模型研发动辄千万美元投入的当下,DeepSeek R1公开的训练成本数据引发行业震动:660B参数规模的模型总训练成本仅29.4万美元(约合人民币208万元),不足国际同级别模型的1/50。这一数据来自《Nature》论文补充材料中的详细披露,涵盖从基础模型到强化学习调优的全流程成本。
2.1 训练成本明细:512张H800 GPU如何实现低成本训练
DeepSeek R1的训练分为两个阶段:基础模型R1-Zero与优化模型R1。前者使用512张H800 GPU训练198小时,后者在此基础上继续训练80小时,单GPU小时成本控制在2美元。具体数据如下:
| 训练阶段 | GPU配置 | 训练时长(小时) | 单GPU小时成本(美元) | 阶段成本(美元) | 参数规模 |
|---|---|---|---|---|---|
| R1-Zero | 512×H800 | 198 | 2 | 202,752 | 660B |
| R1 | 512×H800 | 80 | 2 | 81,920 | 660B |
| 合计 | - | - | - | 284,672 | - |
Tips:大模型训练成本通常由“GPU数量×训练时长×单GPU小时成本”构成。H800作为当前主流AI训练芯片,单卡小时成本普遍在3-5美元,而DeepSeek通过优化并行计算架构和任务调度,将成本压缩至2美元,同时通过高效数据利用减少了30%的无效训练时长。
对比来看,OpenAI GPT-4的训练成本据测算超过1亿美元,谷歌Gemini Ultra约8000万美元,即便是国内同等参数规模的模型,训练成本也多在千万人民币级别。DeepSeek R1的低成本路径,为中小团队突破大模型研发壁垒提供了可行范式。
3. 纯强化学习驱动推理突破:不依赖人工标注的技术路径
DeepSeek R1最核心的技术突破在于其“纯强化学习”训练框架。传统大模型提升推理能力时,需依赖人工标注的“思维链”(Chain-of-Thought)数据,成本高昂且易引入偏见。而R1完全摆脱这一依赖,仅通过最终答案的正确性作为奖励信号,让模型自我演化推理能力。
3.1 从15.6%到71.0%:AIME测试中的推理跃升
在国际数学竞赛AIME(美国数学邀请赛)的测试中,基础模型DeepSeek-V3-Base的pass@1分数仅为15.6%,而经过纯强化学习(GRPO算法)训练后的R1-Zero,分数直接跃升至71.0%,采用多数表决策略后更是达到86.7%,与OpenAI o1(85.3%)的表现不相上下。这一结果表明,不依赖人工标注数据,模型也能自主掌握复杂推理逻辑。
Tips:GRPO(Group Relative Policy Optimization)是DeepSeek团队提出的强化学习优化算法,通过动态调整奖励函数和策略更新步长,解决了传统RLHF(基于人类反馈的强化学习)中“奖励信号稀疏”和“策略坍缩”问题,使模型在数学、编程等需要多步推理的任务上表现显著提升。
4. 数据透明与安全可控:大模型研发的“中国范式”
此前行业对大模型数据来源的透明度一直存在争议,而DeepSeek R1在论文中首次公开了完整的数据集构成,打破了“模型输出数据回灌训练”的传言。其训练数据涵盖五大类,总量超10万条,均经过严格清洗与去重。
4.1 数据集结构:从数学题到角色扮演的多元覆盖
| 数据类型 | 题目数量 | 核心内容示例 |
|---|---|---|
| 数学 | 26,000 | 定量推理题、竞赛题(如IMO、AIME) |
| 编程 | 25,000 | 算法竞赛题(17,000题)、代码修复(8,000例) |
| STEM | 22,000 | 物理、化学、生物等学科选择题(涵盖中学至大学本科难度) |
| 逻辑 | 15,000 | 真实场景逻辑题、合成逻辑推理任务 |
| 通用 | 66,000 | 创意写作、文本编辑、事实问答、角色扮演、无害性评估 |
在安全性方面,DeepSeek发布的专项评估报告显示,R1在六大国际安全基准(如HarmBench、TruthfulQA)上的表现处于中等水平,与GPT-4o相当。其内置的风险控制系统可识别并拒绝98.3%的恶意请求,在多语言安全性测试中,中文场景的识别准确率(97.5%)高于英文(92.1%)。
5. 开源生态与全球影响力:从实验室到产业落地的桥梁
DeepSeek R1不仅在学术上取得突破,更通过开源推动了全球AI社区的发展。团队已在Hugging Face平台公开R1及R1-Zero的模型权重,并开源了基于Qwen2.5-32B、Llama3-70B等小模型的蒸馏版本,让中小企业和研究者也能低成本使用高性能推理能力。
5.1 社区影响力:1090万次下载背后的产业价值
截至目前,DeepSeek R1在Hugging Face的下载量已突破1090万次,位居开源大模型榜首,GitHub仓库Star数达91,100,谷歌学术引用量3596次,成为被引用最多的中国大模型论文之一。这些数据表明,其技术方案已被全球开发者广泛采纳。
5.2 知识蒸馏:大模型赋能小模型,降低产业门槛
为解决大模型部署成本高的问题,DeepSeek团队还展示了“知识蒸馏”技术:以Qwen2.5-32B为基础模型,通过蒸馏R1的推理能力,使其在数学推理任务上的表现提升42%,超过直接对小模型进行强化学习训练的效果。这一方法已被国内多家AI企业用于智能客服、代码助手等场景,显著降低了高性能AI的落地成本。
6. 中国AI的下一个里程碑:从单点突破到生态崛起
DeepSeek R1的登顶并非孤例,而是中国AI整体实力提升的缩影。近年来,阿里通义、字节Seed、腾讯混元、百度文心、华为盘古等团队在多模态理解、行业大模型等领域持续突破,形成“基础研究-技术转化-产业应用”的完整生态。正如梁文锋在论文致谢中所言:“中国AI不可能永远跟随,我们正从技术追随者成长为规则制定者。”
随着更多中国团队登上国际顶级学术舞台,全球AI竞争的重心正逐渐向中国倾斜。DeepSeek R1的故事证明,通过技术创新和开源协作,中国AI不仅能实现“从0到1”的突破,更能引领全球行业的可持续发展。
评论