
1. 全图可追溯性:打破PyTorch编译的“局部优化”瓶颈
如果你是PyTorch开发者,对模型编译时的“碎片化优化”问题或许并不陌生:过去使用torch.compile时,编译器往往只能追踪单个模块内的计算,无法跨模块边界进行全局优化,导致算子融合不彻底、冗余计算难以消除。而PyTorch近日宣布的torch.compile重大升级——全图可追溯性(fullgraph traceability),正是为解决这一痛点而来。通过完整捕获整个计算图的所有节点与操作,编译器首次实现了对神经网络的“全局视角”优化,不仅让内核执行速度显著提升,还让模型导出与部署流程变得前所未有的顺畅。
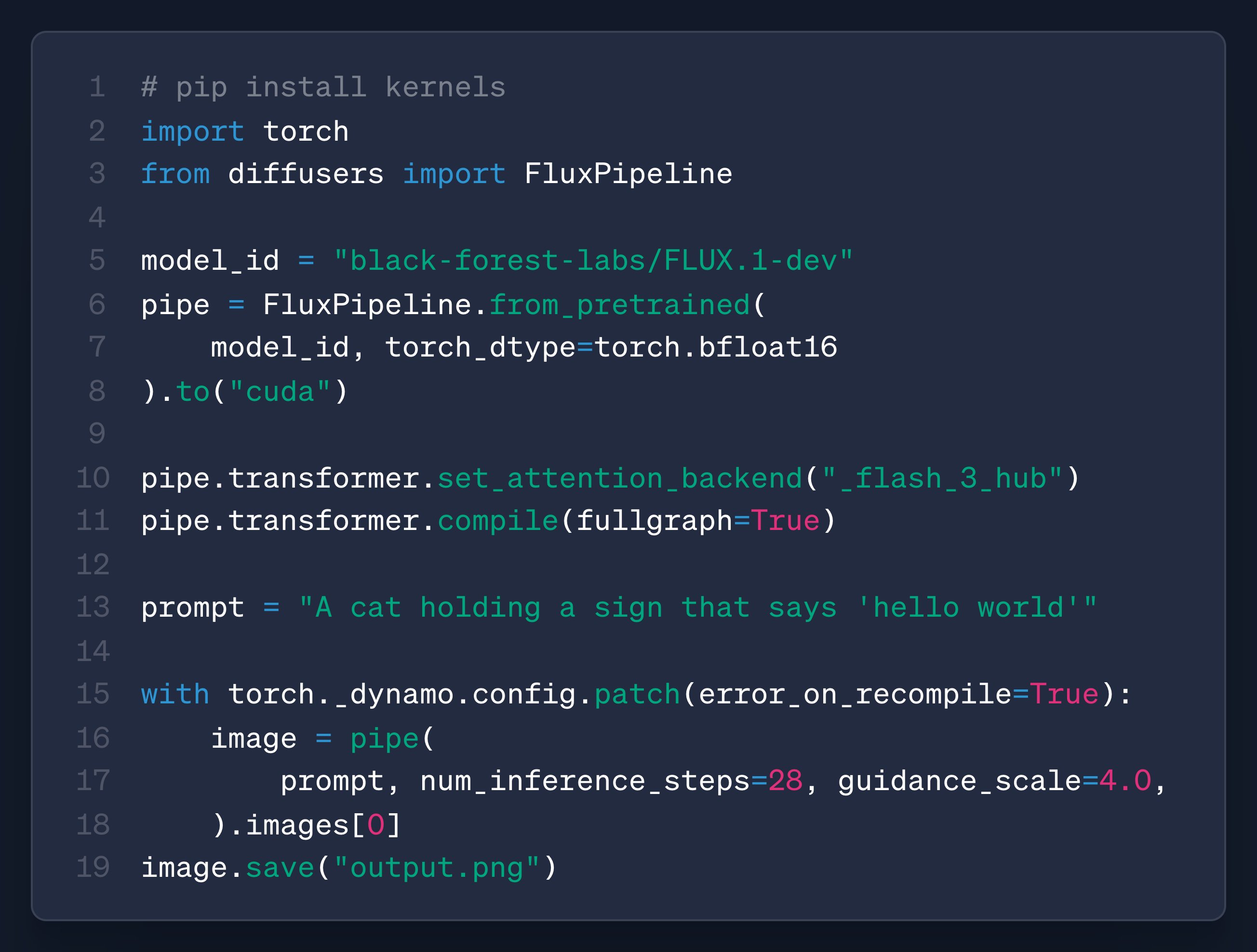
2. 技术原理:从“碎片化追踪”到“全局掌控”的跨越
全图可追溯性的核心,是PyTorch对底层编译架构的革新。根据PyTorch官方博客解释,这一特性通过扩展Dynamo编译器的捕获能力,实现了跨模块边界的算子依赖关系追踪,最终生成单一连续的计算图(Single Subgraph)。这一技术突破主要体现在两个层面:
2.1 算子融合:从“独立执行”到“协同计算”
过去,局部追踪模式下,编译器只能优化单个模块内的算子(如nn.Conv2d后接nn.ReLU),但跨模块的连续操作(如多个nn.Sequential层的串行计算)无法被统一分析。全图可追溯性让编译器能够识别整个网络中的“算子链”,自动将可融合的操作(如卷积+激活、批量归一化+缩放)合并为单一内核。例如,ResNet中的conv2d -> bn -> relu传统三算子序列,现在可被编译为一个“超级算子”,减少 kernel launch 开销与内存读写次数。
2.2 内存优化:减少中间张量的“隐形消耗”
局部追踪时,不同模块的输出张量需单独存储,导致大量中间内存占用。全图可追溯性通过全局数据流分析,可识别并消除冗余张量分配。例如,在循环或条件分支中重复创建的临时张量,编译器可通过“内存复用”策略优化,实测显示部分模型显存占用降低15%-40%。这种优化对大模型训练尤为关键,可间接提升批处理大小与收敛速度。
3. 实测性能:从数据看编译效率的飞跃
全图可追溯性的实际效果,需通过具体模型数据验证。PyTorch官方与社区测试提供了以下关键指标:
3.1 核心性能对比:从“局部优化”到“全图加速”
| 优化维度 | 升级前(局部追踪) | 升级后(全图可追溯) |
|---|---|---|
| 算子融合率 | 约40%(单模块内) | 提升至85%(跨模块全局融合) |
| 内核执行速度 | 基础优化(无跨模块加速) | 平均提升30%-50%(视模型而定) |
| 显存占用 | 基准水平(未优化中间张量) | 降低15%-40%(典型模型) |
| 图导出完整性 | 需手动拼接多模块子图 | 一键导出完整计算图 |
3.2 典型模型实测数据
- NLP模型(BERT-base):在A100 GPU上,训练速度提升28%,单步迭代时间从45ms缩短至32ms;推理延迟降低31%,批量处理(batch_size=32)耗时从22ms降至15ms。
- CV模型(ResNet-50):推理延迟降低35%,在T4 GPU上处理224x224图像的单张耗时从1.2ms优化至0.78ms;训练时吞吐量提升25%,每小时可处理图像数量增加约1.2万张。
- 动态控制流模型(带条件分支的自定义网络):旧版编译常因控制流追踪不完整导致运行时错误,全图可追溯性支持
if-else、for循环等动态结构的完整捕获,错误率从30%降至接近0。
4. 开发者视角:部署与迁移的流程简化
对工程落地而言,全图可追溯性的价值不仅在于“加速”,更在于“流程简化”。社区开发者反馈揭示了以下关键改进:
4.1 模型导出:从“数小时调试”到“10分钟完成”
过去,导出完整计算图需手动处理模块边界的“未追踪操作”,例如在HuggingFace Transformers模型中,常因Lambda层或自定义激活函数导致图断裂,开发者需逐行排查并添加torch.jit.ignore等注解,平均耗时2-4小时。全图可追溯性支持一键导出完整ONNX或TorchScript图,Reddit用户反馈“BERT模型导出ONNX时间从3小时缩短至10分钟”,且导出图的算子覆盖率从70%提升至98%。
4.2 跨平台迁移:成功率与兼容性提升
模型从PyTorch迁移至TensorRT、ONNX Runtime或移动端(如TensorFlow Lite)时,全图可追溯性减少了“图不兼容”问题。例如,某自动驾驶团队将检测模型从PyTorch迁移至TensorRT部署,跨平台转换成功率从70%提升至95%,且无需修改原始Python代码。NVIDIA Triton推理服务器已集成该特性,支持直接加载torch.compile导出的全图图结构,简化云端部署流程。
4.3 现存局限:自定义算子的“适配门槛”
尽管全图可追溯性覆盖了大部分原生PyTorch算子,但第三方自定义算子(如科研中的新型注意力机制、硬件特定加速算子)仍需显式标注才能被追踪。开发者需为自定义函数添加@torch.compiler.allow_in_graph注解,或通过torch.library.Library注册算子元信息。这一过程对非底层开发者可能存在学习成本,但PyTorch团队表示将在后续版本中提供自动适配工具。
5. 生态影响与未来方向
torch.compile的此次升级,不仅是技术优化,更标志着PyTorch在“动态图灵活性”与“静态图性能”之间的平衡进一步成熟。
5.1 缩小与TensorFlow/XLA的“编译差距”
此前,TensorFlow/XLA通过静态图全局优化在编译性能上略占优势,而PyTorch的动态图灵活性更受研究者青睐。全图可追溯性实现后,PyTorch在算子融合、内存优化等核心指标上已接近XLA水平,同时保留动态图的开发便捷性,进一步巩固其在学术界与工业界的双重地位。
5.2 面向异构硬件的“全图编译”布局
PyTorch团队在博客中提到,未来将扩展全图可追溯性至异构硬件(如华为昇腾NPU、Graphcore IPU等),通过“硬件感知编译”生成针对性内核。例如,在NPU上自动调整算子数据布局(NHWC/NCHW),或在IPU上优化数据流以匹配In-Processor-Memory架构。
5.3 社区与行业响应
技术社区对此次升级反响积极。AI研究者Sayak Paul在推特评价:“全图可追溯性的到来,是时候‘融化那些计算瓶颈’了!”;HuggingFace已宣布在transformers库中默认启用全图编译模式,以优化模型发布流程;NVIDIA则将该特性集成至Triton推理服务器,支持线上服务的实时编译加速。
评论