PyTorch[1]
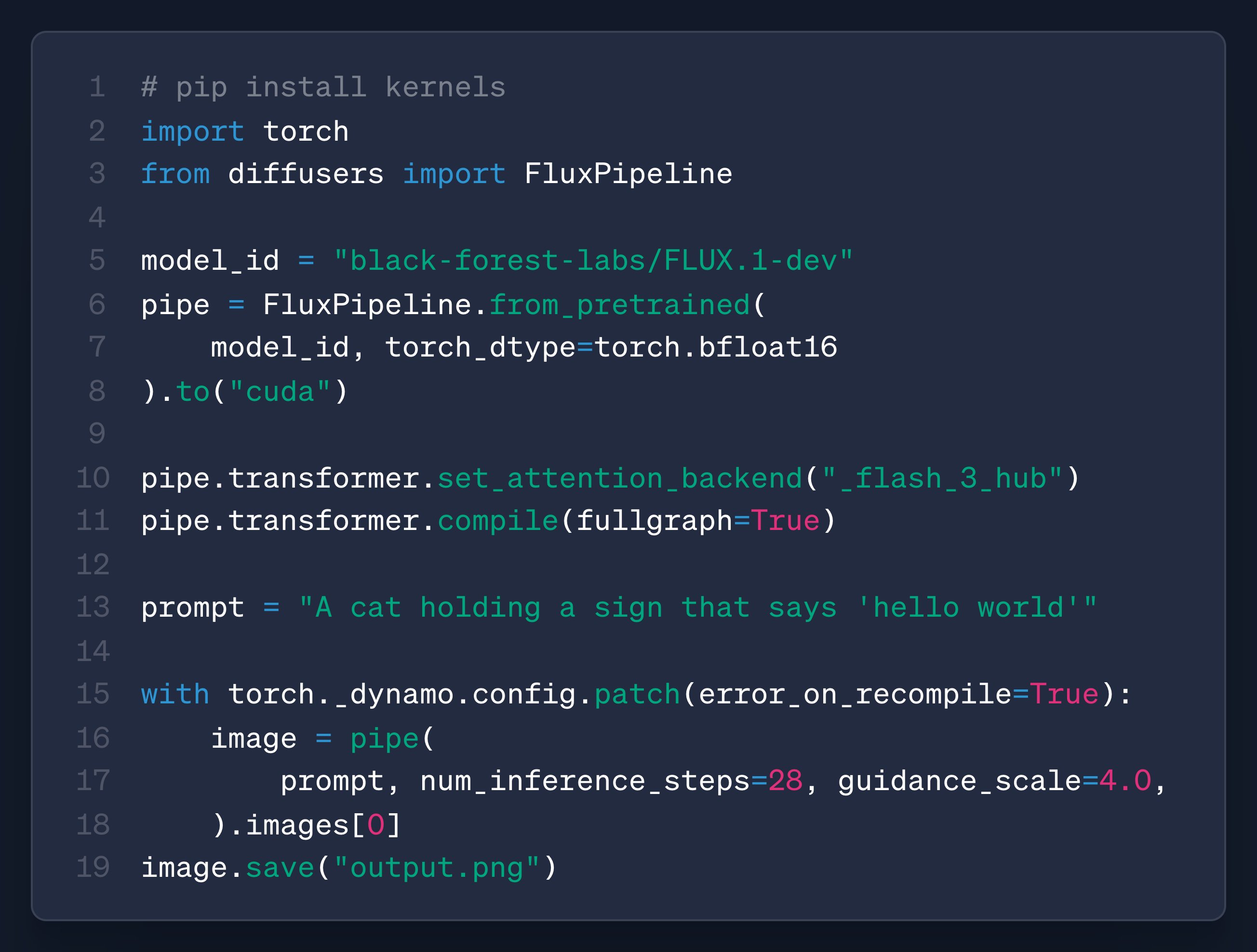
PyTorch torch.compile升级:全图可追溯性打破局部优化瓶颈,性能大幅提升
PyTorch的torch.compile迎来重大升级,推出“全图可追溯性”功能,彻底打破模型编译的“局部优化”瓶颈。该特性通过革新底层编译架构,实现跨模块算子依赖追踪与单一计算图生成,使算子融合率从40%提升至85%,并通过全局内存优化减少15%-40%显存占用。实测显示,BERT训练速度提升28%,ResNet推理延迟降低35%,动态控制流模型错误率降至接近零。开发者部署流程大幅简化,模型导出时间从数小时缩至10分钟,跨平台迁移成功率提升至95%。目前HuggingFace、NVIDIA Triton等已集成该特性,助力大模型训练与推理效率飞跃。
