
1. 数字人实时交互的技术瓶颈:从延迟难题到多模态挑战
数字人技术正从静态展示走向动态交互,在虚拟主播、在线教育、元宇宙社交等场景中扮演越来越重要的角色。但要实现「像真人一样自然对话、实时响应」,行业长期面临两大核心难题:高延迟与多模态融合。多数现有方案要么需要依赖高性能GPU集群才能勉强实现秒级响应,要么只能处理单一文本或语音输入,难以兼顾动作、表情、环境互动的协同控制。例如,某主流数字人系统在处理双人对话时,端到端延迟常超过1.5秒,导致对话节奏卡顿;而单纯依赖文本驱动的数字人,又会因缺乏语音、姿态等模态输入,表情动作显得僵硬机械。
正是在这样的背景下,快手可灵团队(Kling Team)近日发布了全新框架MIDAS(Multimodal Interactive Digital-human Synthesis),通过底层技术创新将数字人实时交互的延迟压缩至500毫秒以下,并首次实现音频、文本、姿态等多模态信号的无缝协同控制。这一突破不仅让数字人「活」得更自然,更为实时交互场景提供了可行的技术路径。
2. MIDAS框架:破解实时交互难题的核心指标与整体设计
MIDAS框架的核心目标是「低延迟下的高质量多模态生成」。从技术指标来看,它交出了一份亮眼的答卷:
| 技术特性 | 具体描述 | 性能表现 |
|---|---|---|
| 高压缩比自编码器 | 自研DC-AE(Dense Compression Autoencoder),将图像压缩为少量令牌 | 64倍压缩,每帧最多60个token |
| 端到端生成延迟 | 流式交互响应时间 | <500ms(实测480ms级别) |
| 扩散去噪效率 | 轻量级扩散头优化去噪步骤 | 仅需4步扩散完成高清渲染 |
| 多模态支持能力 | 统一处理音频、文本、姿态等输入 | 支持跨模态协同控制 |
从整体架构来看,MIDAS采用「自回归预测+扩散渲染」的双阶段设计:先用自回归模型(类似大语言模型的逐词生成逻辑)逐帧预测图像的潜在表示,再通过轻量级扩散头将潜在表示转换为高清视频帧。这种设计既保证了时序连贯性(自回归模型擅长长序列生成),又通过压缩和简化渲染步骤大幅降低了延迟。
3. MIDAS的三大技术突破:如何实现低延迟与多模态融合
3.1 多模态指令控制:让数字人「听懂」声音、「看懂」动作
传统数字人系统处理多模态输入时,常因各模态信号独立编码导致「动作-表情-语音」脱节——比如文本说「开心」,表情却滞后半秒,或姿态输入与语音节奏不匹配。MIDAS通过「统一多模态条件投影器」解决了这一问题:
所有输入信号(音频、文本、姿态数据)会先被编码到同一个「共享潜在空间」,生成全局指令令牌。例如,用户输入语音时,系统会同步提取语音的情感特征(如语调高低)、文本语义(如「你好」的问候意图),以及姿态传感器捕捉的手势动作,将这些信息融合为一组令牌,再逐帧注入自回归模型。这种设计确保数字人的动作、表情、口型能与多模态输入高度同步,甚至能根据「倾听姿态」(如点头、眼神关注)判断对话节奏,实现自然的轮流交互。
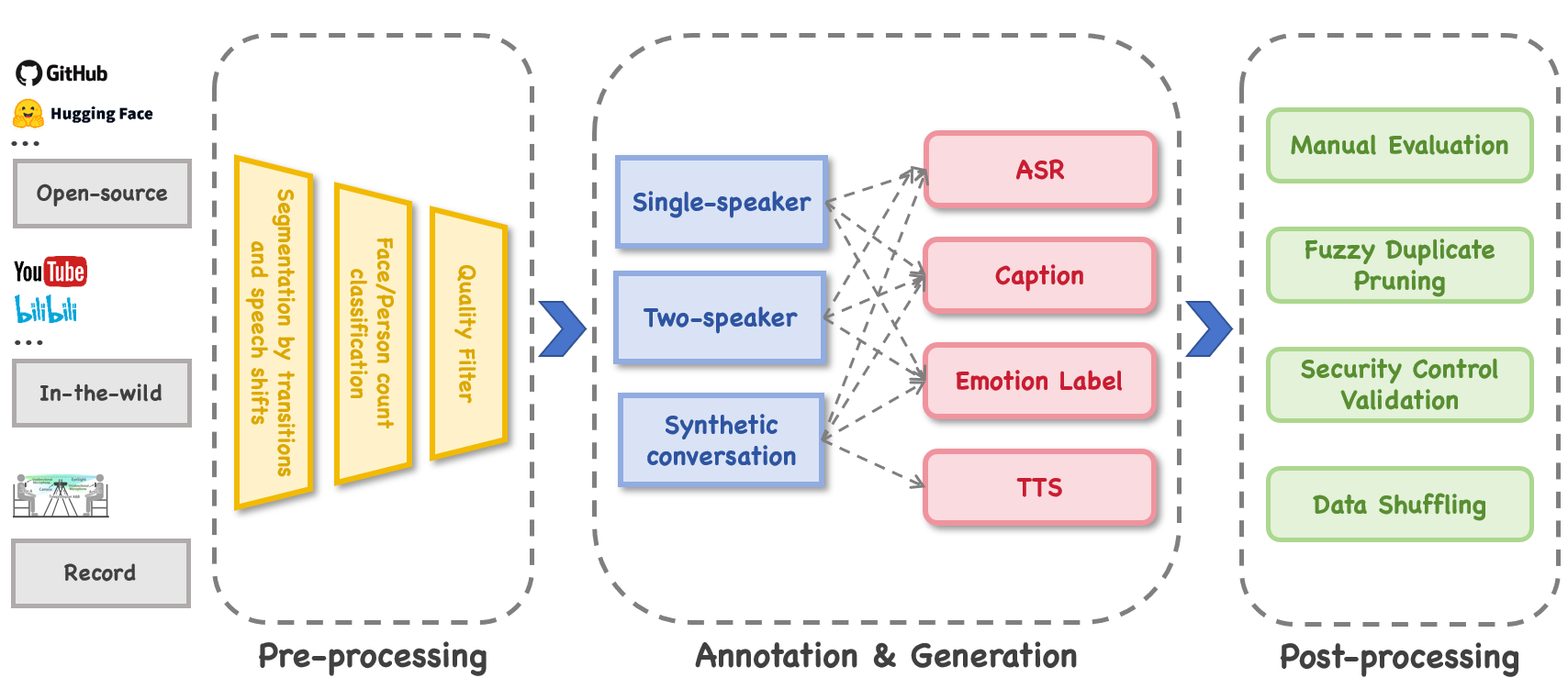
在多模态指令控制中,需要对来自不同来源(如 GitHub、Hugging Face 等开源平台,YouTube、bilibili 等视频平台,以及实际录制等 “野外” 数据)的多模态数据进行处理。这张图展示的从数据预处理(包括分割、分类、质量过滤等),到标注与生成(针对单 speaker、双 speaker、合成对话等进行 ASR、字幕、情感标签、TTS 等处理),再到后处理(人工评估、去重、安全验证、数据打乱等)的完整流程,正是为多模态指令控制提供高质量、经过处理的多模态数据的关键环节。这些处理后的数据能更好地被编码到 “共享潜在空间”,生成全局指令令牌,从而让数字人的动作、表情、口型等与多模态输入高度同步。
Tips:什么是「共享潜在空间」?
潜在空间是AI模型将原始数据(如图像、文本)压缩后的低维表示空间。多模态信号进入同一潜在空间后,模型能直接学习不同模态间的关联(如「笑声」对应「嘴角上扬」的表情特征),从而实现更精准的协同控制。
3.2 因果潜在预测与轻量化扩散渲染:平衡连贯性与速度的「双引擎」
实时生成的核心矛盾是「连贯性」与「速度」的权衡:生成过快可能导致动作跳变,追求连贯又会增加延迟。MIDAS的「因果潜在预测+扩散渲染」架构给出了巧妙解法:
- 因果潜在预测:自回归模型(基于Qwen2.5-3B大语言模型架构)以「因果时序」方式逐帧预测图像的潜在表示。「因果」意味着模型生成当前帧时,只会依赖历史帧信息(类似人说话不会提前预知下一句),避免未来信息导致的「延迟累积」。
- 轻量化扩散渲染:传统扩散模型需要数十步甚至上百步去噪才能生成图像,而MIDAS的扩散头仅需4步。这得益于两方面优化:一是输入的潜在表示已高度结构化(由自回归模型生成),二是扩散头采用MLP(多层感知机)简化网络结构,专注于细节修复而非从头生成。
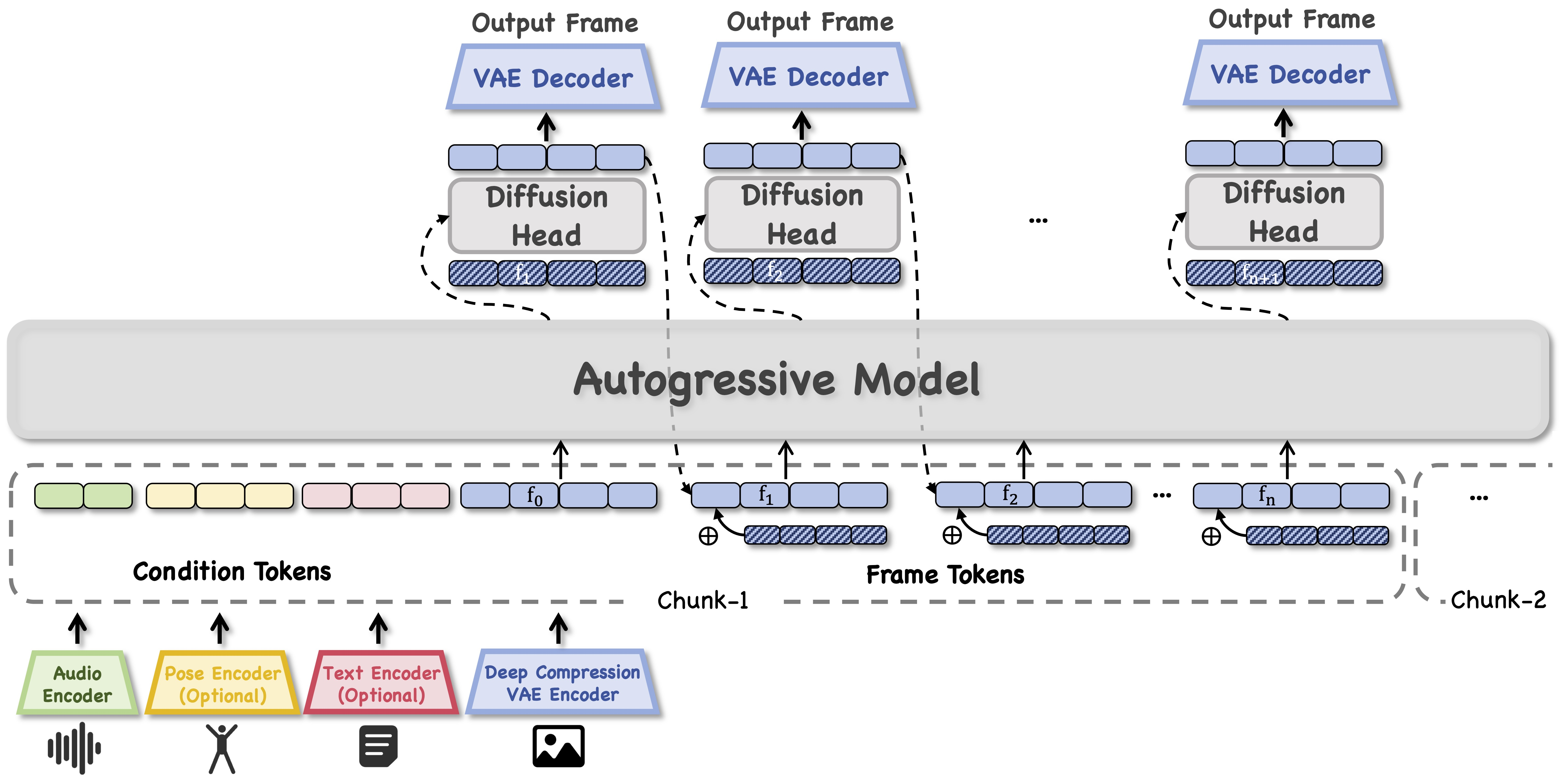
自回归模型逐帧预测图像潜在表示,通过扩散头结合 VAE 解码器将潜在表示转换为高清视频帧的过程,同时还体现了多模态条件(音频、姿态、文本等)如何输入到自回归模型中。这与该部分中自回归模型逐帧预测潜在表示以保证时序连贯性,以及轻量化扩散头快速渲染高清帧以降低延迟的内容高度契合,能直观地说明 “双引擎” 是如何平衡连贯性与速度的。
Tips:4步扩散如何保证图像质量?
扩散模型的去噪步骤越多,生成图像越精细,但耗时也越长。MIDAS通过高压缩自编码器将图像压缩为60个token,潜在空间的信息密度极高,因此即使仅用4步去噪,也能保留关键细节(如面部表情、肢体动作),满足实时交互的视觉需求。
3.3 64倍压缩自编码器:让每帧图像「瘦身」为60个令牌
要实现自回归模型的高效运行,必须大幅降低每帧图像的数据量——这就像写文章时,用简洁的大纲(而非全文)来构思下一段落会更快。MIDAS的DC-AE自编码器正是这一「瘦身工具」:
它能将一帧384×640分辨率的图像(约98万像素)压缩为最多60个token,压缩比达64倍。具体来说,DC-AE通过编码器提取图像的语义特征(如「面部区域」「肢体姿态」)和空间结构(如「眼睛位置」「手势方向」),再用解码器将token重建为图像。为避免压缩导致的细节丢失,团队还加入了「因果时序卷积」和「RoPE注意力机制」,让模型在压缩时记住前后帧的动作关联(如挥手动作的连贯性)。
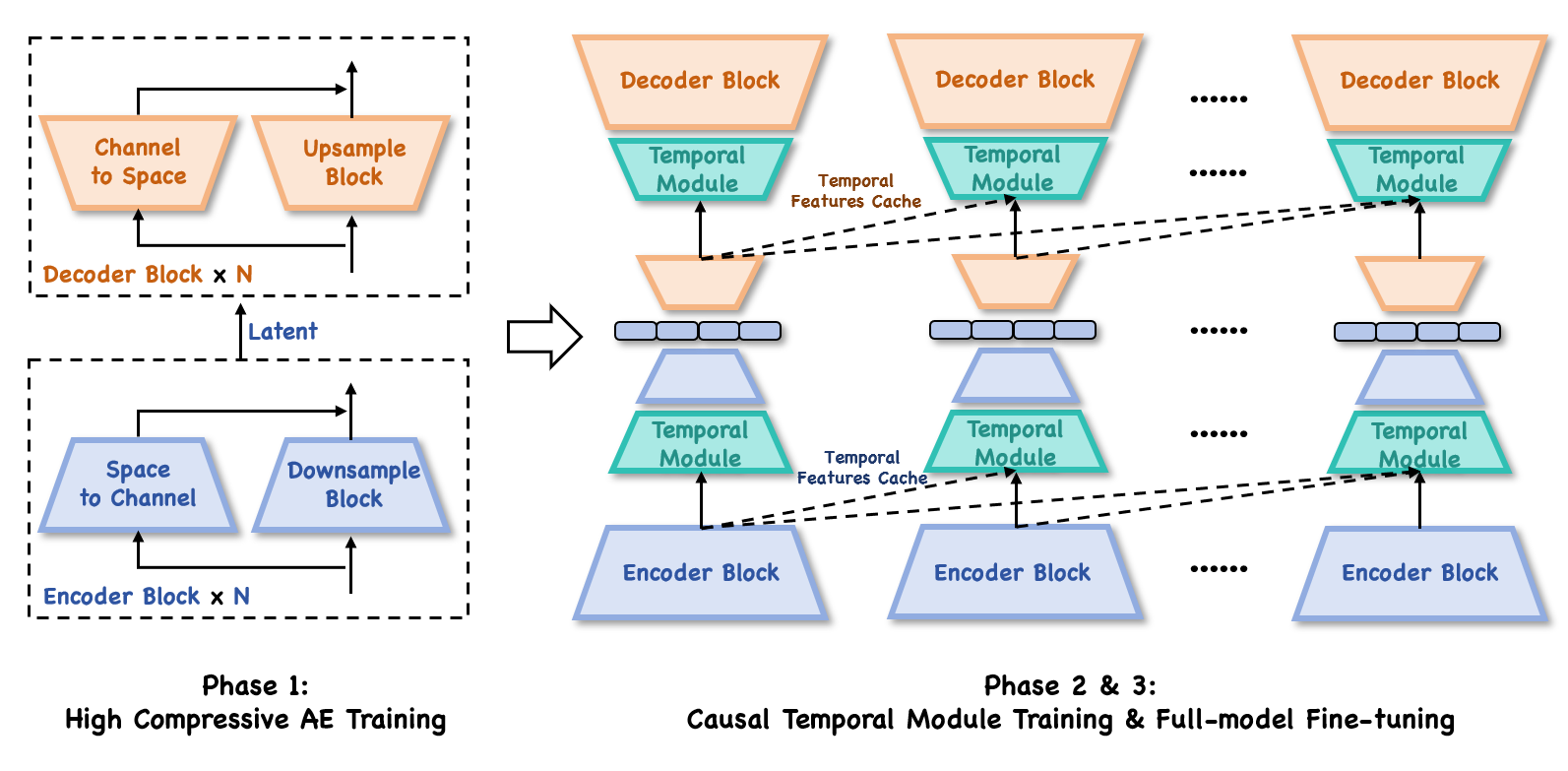
模型训练的不同阶段,包括高压缩自编码器训练(Phase 1)以及后续的因果时间模块训练和全模型微调(Phase 2 & 3)。高压缩自编码器的训练是 DC - AE 能够将图像有效压缩为少量令牌的基础,通过这些训练阶段,自编码器能更好地提取图像的语义特征和空间结构,同时记住前后帧的动作关联,避免压缩导致的细节丢失,从而为后续自回归模型和扩散渲染提供高质量的压缩后表示。
Tips:自编码器在数字人生成中的作用
自编码器本质是「数据压缩-重建工具」,但在数字人领域,它的价值远不止于此:通过压缩,模型能聚焦于「动作语义」(如「点头表示同意」)而非像素级细节,从而更快生成符合指令的动作;同时,压缩后的token可直接输入自回归模型,大幅降低计算量。
4. 从实验室到落地:MIDAS框架的三大典型应用场景
技术的价值最终要通过场景落地体现。MIDAS在测试中展现出对多场景的适配能力,以下三个案例尤为典型:
4.1 双人实时对话:让数字人「自然聊天」成为可能
在双人对话场景中,MIDAS能实时处理双方的音频流,生成同步的口型、表情和倾听姿态。例如,当用户说「今天天气不错」时,数字人会先通过音频分析判断「陈述语气」,同步生成点头(表示倾听)和微笑表情,随后根据预设对话逻辑回应「是啊,很适合出门」,同时口型与语音完全匹配。整个过程端到端延迟低于500ms,对话节奏接近真人面对面交流。
4.2 跨语言歌唱合成:数字人也能「唱」多国语言
传统歌唱数字人常受限于单一语种,且唇形与歌词发音的匹配度低。MIDAS通过多模态融合技术,支持中、日、英等多语种歌曲生成:输入歌词文本和旋律音频后,系统会先将文本转换为语音,再根据语音的音素特征(如中文的「声母-韵母」、英文的「音节重音」)生成精准唇形,同时结合旋律节奏调整肢体动作(如挥手、点头)。测试显示,其生成的4分钟歌曲视频中,唇形同步误差小于0.1秒,且无明显动作漂移。
4.3 交互式世界建模:数字人「走进」虚拟场景
除了对话和表演,MIDAS还能与虚拟环境实时互动。在Minecraft(我的世界)测试中,用户通过方向键控制虚拟角色移动时,MIDAS生成的数字人会根据场景变化调整动作——比如遇到障碍物时自动弯腰,进入房间后转头观察四周。这得益于其「交互式世界建模」能力:系统会将环境信息(如障碍物位置、空间大小)作为额外模态输入,让数字人的动作与虚拟世界逻辑一致。
5. 技术意义与未来:数字人交互的下一个里程碑?
MIDAS的发布不仅是技术指标的突破,更重新定义了数字人实时交互的「可能性边界」。其模块化设计(自回归模型和扩散头可独立替换)意味着未来可接入更强的自回归模型(如更大参数的语言模型)或更高效的渲染器,进一步提升生成质量和降低延迟。
对于行业而言,这一技术可能加速数字人在直播、教育、客服等场景的落地:虚拟主播可实时回应观众弹幕,在线教师能根据学生的表情反馈调整讲课节奏,智能客服则能通过语音和肢体语言传递更亲切的服务体验。
快手可灵团队表示,下一步将重点优化高分辨率生成能力(目标720P/1080P)和复杂场景交互逻辑(如多人同时对话时的注意力分配)。随着技术的成熟,或许不久后,我们就能在手机端与「活灵活现」的数字人实时聊天、唱歌甚至共同探索虚拟世界。
评论