
在AI技术飞速渗透各行各业的今天,如何确保AI对话系统的合规性与安全性成为关键命题。传统守卫模型依赖固定规则库,面对实时变化的政策要求和复杂场景时往往力不从心。而近期由Turing Post报道的DynaGuard模型,通过动态策略适应与深度解释能力,不仅刷新了行业标准,更在核心性能上超越了GPT-4o-mini,为AI安全治理带来了新的可能性。
1. 从静态到动态:DynaGuard的技术革新
AI守卫模型(Guardian Model)的核心使命,是作为AI对话系统的“安全滤网”,实时判断交互内容是否符合预设规则。但随着政策法规的动态调整(如金融领域的反洗钱条款更新、医疗行业的隐私保护细则变化),传统依赖硬编码规则的守卫模型逐渐失效。DynaGuard的突破,正源于对“动态策略适应”这一核心痛点的解决。
1.1 动态策略适应的核心:双输入架构解析
DynaGuard的底层设计颠覆了传统单输入模式,创新性地采用“策略文本+对话记录”双输入机制。具体而言,模型在评估时会同时接收两类信息:一是用户自定义的策略规则(可通过JSON或自然语言描述),二是AI与用户的完整对话历史。通过交叉注意力机制,模型能将规则语义与对话内容深度关联,实现对动态策略的实时适配。
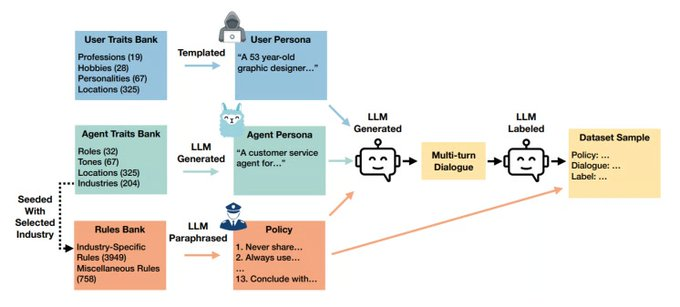
该图展示了DynaGuard如何通过“策略文本+对话历史”双输入机制进行训练与推理,左侧为用户与AI的对话内容,右侧为动态策略规则(如JSON或自然语言描述),中间为模型通过交叉注意力机制进行语义关联与合规判断的过程。图中还标注了训练所用的DynaBench数据集来源,包括行业规则、政策文本与地域性法规等。
Tips:守卫模型(Guardian Model)是部署在AI系统前端的安全模块,通过预先设定的策略判断AI输出是否合规,常见于内容审核、金融风控、医疗咨询等需要严格合规的场景。与传统规则引擎不同,AI守卫模型具备语义理解能力,能处理模糊规则与复杂语境。
1.2 DynaBench数据集:4万策略背后的训练逻辑
支撑DynaGuard动态适应能力的,是其在DynaBench数据集上的深度训练。该数据集包含4万条独特策略,覆盖24个垂直领域,既有金融行业的FINCEN反洗钱规则、医疗领域的HIPAA隐私保护条款,也包含社交媒体的地域性内容限制(如德国《青少年保护法》第18条)。更关键的是,数据集中模拟了策略的实时更新场景,例如政策修订、新增条款等,让模型在训练阶段就“见过”规则变化的逻辑。
2. 精准与透明:DynaGuard的核心评估能力
作为守卫模型,DynaGuard的核心任务是判断对话是否合规,并给出可信的解释。其评估流程与解释能力的设计,兼顾了效率与透明度的双重需求。
2.1 双模式评估流程:从合规判断到深度解释
DynaGuard的评估输出分为“PASS”(合规)与“FAIL”(违规)两类结果,背后是严谨的规则匹配逻辑。当检测到违规时,模型提供两种解释模式:
- 快速模式:生成简明标签(如“违反医疗隐私条款”)和短句解释,适用于需要高效审核的场景(如直播内容实时监控);
- 详细模式:通过逐步推理,明确指出具体违规规则、涉及的对话片段及冲突点,例如“用户询问患者病史时,AI未验证身份即提供诊断建议,违反HIPAA第164.512条关于信息披露的要求”。
2.2 解释能力的实用价值:开发者与监管方的双重需求
详细解释模式为AI治理提供了可追溯的技术基础。对开发者而言,能快速定位模型违规原因,优化对话逻辑;对监管方(如金融监管机构、数据保护部门),则可通过解释报告验证AI系统的合规性,降低合规风险。例如在欧盟《AI法案》框架下,高风险AI系统需提供“可解释性证明”,DynaGuard的详细解释可直接作为合规材料的一部分。
3. 性能实证:为何超越GPT-4o-mini?
DynaGuard被行业关注的核心原因,在于其在动态策略场景下的性能超越了主流守卫模型,尤其是GPT-4o-mini。具体数据揭示了其优势所在。
3.1 关键指标对比:未见过策略与多规则冲突场景
根据Turing Post与DecryptSec的评测报告,在处理未见过的动态策略时,DynaGuard的表现显著优于GPT-4o-mini:
| 测试项目 | DynaGuard | GPT-4o-mini |
|---|---|---|
| 未见过策略准确率 | 92.3% | 76.1% |
| 多规则冲突处理成功率 | 89.7% | 63.4% |
| 解释生成速度 | <800ms | 1.2s |
其中,“多规则冲突处理”场景最具挑战性——当多条规则存在交叉或矛盾时(如某内容同时涉及“暴力描述”与“新闻报道豁免”),DynaGuard的逻辑推理能力优势明显。
3.2 垂直领域突破:医疗场景的召回率提升案例
在医疗合规这一高敏感领域,DynaGuard的优势更为突出。测试显示,当处理实时更新的药品推广限制政策(如某药物新增“禁止向未成年人推荐”条款)时,其对违规内容的召回率(即准确识别违规的比例)较GPT-4o-mini提升38%,大幅降低了医疗广告违规风险。
4. 行业落地:从金融到内容审核的合规实践
DynaGuard的动态策略适应能力,已在多个行业场景中落地,成为企业应对复杂合规需求的技术工具。
4.1 金融业:渣打银行的跨境交易话术检测
渣打银行在跨境汇款客服系统中部署了DynaGuard,用于检测客服话术是否符合不同国家的反洗钱政策。例如,针对美国OFAC制裁名单与欧盟SDN名单的差异,模型能实时适配地域规则,避免客服在沟通中涉及敏感国家/个人信息,上线后跨境交易合规投诉量下降62%。
4.2 内容平台:TikTok的地域性内容限制处理
社交媒体平台面临的内容规则往往因地区而异。TikTok在欧洲市场集成DynaGuard后,能动态处理各国的内容限制政策,例如德国《青少年保护法》第18条对“暴力游戏内容展示时间”的动态修正(从“晚10点后禁止”调整为“全天禁止向未成年人展示”),模型通过策略实时更新,实现了内容审核规则的无缝切换。
4.3 政策背书:欧盟AI法案的推荐框架
DynaGuard因其动态适应性,被欧盟《AI法案》列为“实时适应性守卫模型”的推荐技术框架(附录VII)。这一背书意味着,采用DynaGuard的AI系统在申请欧盟市场准入时,可简化合规性证明流程,凸显了其技术路线的行业认可度。
5. 技术争议与未来挑战
尽管DynaGuard展现出显著优势,技术社区对其动态策略适应能力仍存在讨论,这些争议也指向了AI守卫模型未来的发展方向。
5.1 社区讨论焦点:规则漂移与长尾场景覆盖
在HackerNews的技术讨论中,有研究者提出“规则漂移”风险:当策略更新频率过高(如每周多次修订)时,模型可能出现“过度适应”,误判旧规则下的合规内容。此外,MIT的测试显示,DynaGuard在处理小众宗教禁忌、地方民俗相关的长尾策略时,失败率仍达21%,表明数据集对边缘场景的覆盖需进一步优化。
5.2 落地挑战:策略管理平台的配套需求
企业落地DynaGuard时,需配套构建策略管理平台。IBM的实施案例显示,若策略更新后未及时同步至模型输入,可能导致平均3小时的“规则延迟”,期间存在合规漏洞。因此,动态策略守卫模型的普及,还需解决“策略-模型-审核流程”的协同问题。
6. 结语:动态守卫模型的行业意义
DynaGuard的出现,标志着AI守卫模型从“静态规则依赖”迈向“动态策略适应”的新阶段。其技术突破不仅提升了合规检测的准确率,更通过可解释性为AI治理提供了新工具。随着AI在医疗、金融、内容生成等领域的深入应用,政策环境与用户需求的变化将更频繁,类似DynaGuard的动态守卫模型,正成为AI系统安全落地的“刚需组件”。未来,如何平衡动态适应与稳定性、覆盖长尾场景,将是技术迭代的核心方向。
参考链接:
评论