多模态[57]

李飞飞团队研发Marble模型:自动化生成超大规模3D虚拟世界
李飞飞团队Marble 3D世界生成模型,可通过文本或图像提示生成超大规模、细节丰富且空间连贯的虚拟环境,为3D AIGC领域带来新突破。该模型融合扩散模型、NeRF及大型语言模型技术,有望赋能游戏开发、元宇宙构建及自动驾驶模拟训练等场景,引发业界对其计算效率与可控性的关注。

字节跳动港大联合发布Mini-o3:低成本复现并超越o3视觉推理
字节跳动与香港大学联合开发的开源模型Mini-o3,实现多轮视觉推理突破:以最多6轮训练数据,支持测试时数十轮深度推理,解决传统模型训练成本高、推理深度有限痛点。在高难度视觉搜索任务中超越现有开源模型,依托VisualProbe数据集与两阶段训练法,推动机器人视觉、医疗影像等领域应用。
蚂蚁集团推出全球首个智能眼镜可信连接框架gPass 重构数字生活入口
AI眼镜成下一代智能终端,但面临生态碎片化难题。蚂蚁集团推出全球首个智能眼镜可信连接技术框架gPass,以安全、交互、连接为核心,破解软硬件不统一、应用匮乏、服务割裂痛点,构建全链路安全防护、自然多模态交互及跨设备协同标准,已落地支付、文旅、医疗等场景,加速行业普及,重新定义数字生活入口。

快手可灵AI数字人技术公开:从对口型到全身表演,数字人迈入“会表演”时代
快手可灵AI推出Kling-Avatar数字人技术,突破传统数字人僵硬局限,通过多模态大语言模型实现"全身自然表演"。支持文本/音频/图像输入,生成含表情、肢体、情绪的流畅视频,口型精准、动作连贯。技术已开放公测,助力虚拟主播、动画制作等内容创作,重新定义数字人表演边界。
语音语言模型(LSLM)破局:全球首个开源端到端框架LLaSO树立研究新基准
在语音语言模型(LSLM)面临架构碎片化、数据不透明等瓶颈时,北京深度逻辑智能推出全球首个完全开源、端到端语音大模型框架LLaSO。该框架含数据对齐(1200万样本)、指令微调(1350万样本)、评估基准(1.5万测试样本)三大核心组件,解决行业痛点,推动语音AI迈向开放可及未来。
OpenVision 2发布:极简生成式视觉预训练摒弃对比学习,性能效率全面超越CLIP
OpenVision 2掀起视觉预训练“减法革命”,以极简设计挑战CLIP霸权:砍掉文本编码器与对比学习,仅保留图像→描述生成任务,训练效率提升1.5-2倍、显存占用减半,性能媲美CLIP,在OCR、图表理解等细粒度任务更优。依托Recap-DataComp-1B v2高质量数据,推动视觉大模型降门槛。
全球大模型开源生态报告2.0发布:中美贡献超四成核心力量,AI编程工具爆发式增长
《全球大模型开源开发生态全景与趋势报告2.0》发布,蚂蚁开源联合Inclusion AI勾勒AI开源生态。数据显示,62%核心项目诞生于“GPT时刻”后,平均年龄30个月,迭代加速至2-3个月;中美开发者贡献超40%,成“双核引擎”。技术上,MoE架构突破参数瓶颈,多模态成主流,AI编程工具爆发重塑开发流程,中国以开放权重策略推动生态创新。
马拉维农民借AI聊天机器人Ulangizi应对气候危机,农业生产模式悄然变革
马拉维农民灾后借AI助手Ulangizi重获生机。这款基于LLaMA模型、依托WhatsApp的工具,提供病虫害诊断、种植管理及气候适应建议,助农户如Alex Maere改种土豆增收超800美元。Ulangizi推动经验种植转向科学管理,为非洲应对气候变化、农业数字化开辟新路径。

Google Gemini登顶美国App Store免费榜:Nano Banana AI图像编辑模型驱动
Google Gemini登顶美区App Store免费榜,内置Nano Banana AI图像编辑模型成关键。该模型以角色一致性控制(解决主体失真)、多模态交互(支持13图融合、地图标记生成)、高效处理(单次10-20秒)为核心优势,免费用户每日可编100张图,正重塑社交创作、3D打印等场景,成AI图像编辑新标杆。
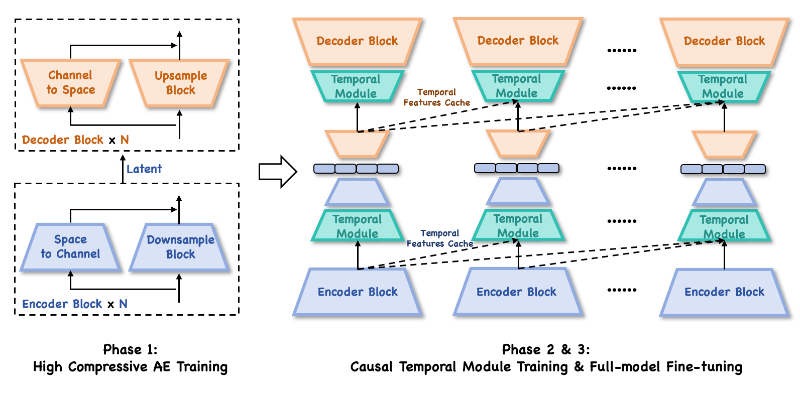
快手可灵团队发布MIDAS框架:64倍压缩与500ms低延迟实现数字人多模态实时交互
快手可灵团队发布MIDAS框架,破解数字人实时交互高延迟与多模态融合难题,端到端延迟<500ms,支持音频、文本、姿态协同控制。通过64倍压缩自编码器、双阶段生成设计,实现自然对话、跨语言歌唱等场景落地,推动虚拟主播、元宇宙社交等领域数字人交互升级。