多模态[57]
生数科技完成数亿元A轮融资 Vidu多模态大模型加速全球布局
生数科技完成数亿元A轮融资,博华资本领投,百度战投等跟投。其核心产品Vidu多模态大模型对标OpenAI Sora,具备图文音视频生成能力,以参考生成、主体库功能解决行业痛点,服务京东、亚马逊等头部客户,ARR超2000万美元,覆盖200+国家,推动AI内容生产变革。

Google Gemini 2.5 Flash Image API上线 开发者生态全面升级
Google DeepMind开放Gemini 1.5 Flash Image API,为开发者提供轻量高效多模态AI能力。该模型具低延迟(提速30%+)、低资源(体积压缩40%)、低成本(较Pro版降60%)特性,支持图像/视频/音频混合输入,100万tokens超大上下文窗口提升处理效率。搭配AI Studio零门槛测试、Gemma开源模型本地化部署、AI Edge跨端方案及代码助手,构建从原型到落地全链路工具生态,推动多模态AI技术普惠化。

xAI发布Grok 4 Fast:2M上下文窗口与统一架构重塑AI成本与智能边界
2025年9月xAI推出多模态大模型Grok 4 Fast,以200万token上下文窗口与统一架构实现98%成本削减,性能接近顶级模型,支持原生工具调用与实时搜索,适配企业级长文档处理、消费级信息整合等全场景,重新定义AI“高性能-低成本”平衡,推动行业普惠化进程。
ICPC 2025:OpenAI与Gemini双双登顶金牌 AI编程能力首次全面超越人类顶尖团队
2025年9月阿塞拜疆巴库ICPC世界总决赛,OpenAI的AI系统首次超越人类团队,以解决全部12道题、零错误提交(最难题目除外)的满分成绩夺冠,Google Gemini解决10题跻身金牌。突破源于AI通用推理能力跃升,未专项训练(“裸奔挑战”),标志AI通用推理正式迈入“人类顶尖水平”,改写ICPC 40余年历史,为编程教育、算法研究等领域带来变革。
Google发布“Learn Your Way”:生成式AI驱动个性化教材,重塑学习体验
Google推出“Learn Your Way”实验项目,以生成式AI打破传统教材“一刀切”困境,通过年级定制(适配认知水平)与兴趣驱动(绑定生活场景)实现双重个性化,结合双重编码理论与LearnLM、Gemini模型,生成多模态学习内容,降低理解门槛,提升效率,助力教育公平,让教材从标准化产品变为“千人千面”的动态学习伙伴。

Llama-Factory发布:推动大模型微调标准化 百余开源模型实现零代码定制
Llama-Factory是获ACL 2024认可的开源大模型微调工具,支持超百种LLMs与VLMs,零代码CLI/Web UI降低操作门槛,集成LoRA等高效训练策略,已被Amazon、NVIDIA等企业采用,助力快速定制适配特定场景的AI模型。
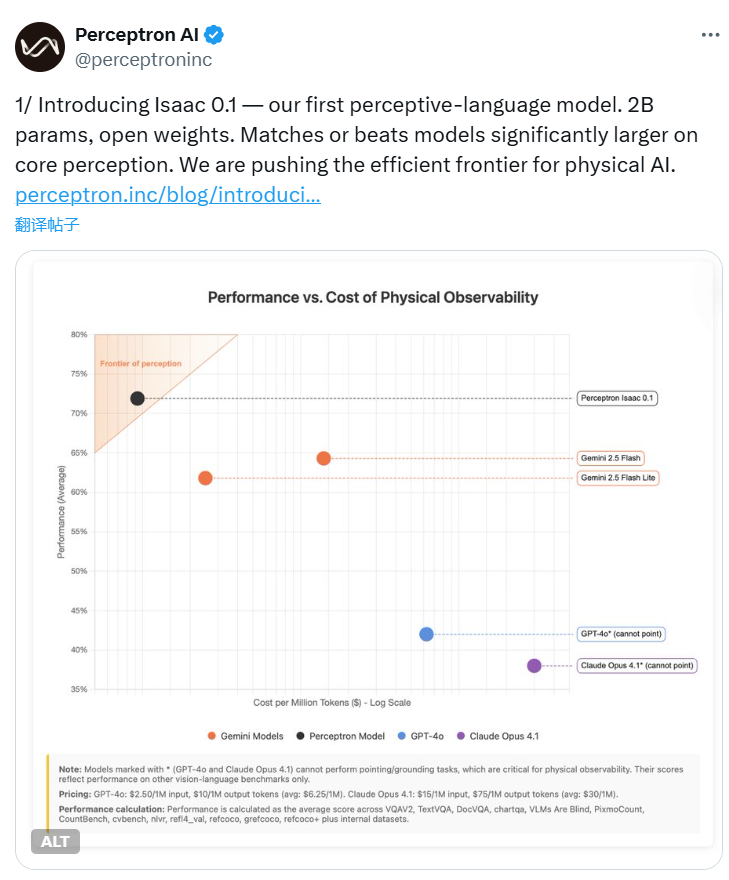
Perceptron发布Isaac 0.1:2B参数开放权重感知语言模型挑战大型模型性能极限
AI初创公司Perceptron发布感知语言模型Isaac 0.1,以20亿轻量级参数,通过统一编码框架甩掉视觉外挂,核心感知任务超越更大模型。开放权重策略加速物理AI落地,适用于机器人、智能家居等场景,开启效率革命新方向。

OpenAI GPTeam 2025 ICPC世界决赛斩获满分 成首支AI冠军团队
2025年9月,OpenAI通用推理模型GPTeam在ICPC世界总决赛中与人类冠军团队并列满分,系AI首次达编程界顶级赛事人类顶尖水平。该模型凭多模态理解、自动调试及团队协作模拟技术突破,标志通用人工智能在复杂推理领域里程碑,将重塑编程教育、科研协作与问题解决模式。
xAI发布Grok 4 Fast:AI响应进入“秒”时代,速度提升十倍
xAI Grok 4 Fast是一款极速AI模型,生成速度达每秒75个token,较标准版提升10倍,实现编程解题、日常问答等场景秒级响应。通过架构优化与速度优先设计,平衡效率与基础准确性,成为用户日常高效交互新工具,开启AI秒响应时代。
慕尼黑工业大学GUIRepair登顶SWE-bench多模态榜单 自动化视觉软件缺陷修复迎来新里程碑
慕尼黑工大GUIRepair框架实现前端视觉bug自动修复突破,以多模态“看见即修复”理念,通过Image2Code和Code2Image组件实现视觉与代码双向理解,登顶SWE-bench Multimodal榜单,修复成功率35.98%刷新SOTA,开启多模态软件工程新范式,提升前端开发效率。