2025服贸会上小猿全系智能软硬件亮相
2025服贸会上,小猿全系智能软硬件亮相,AI学习机T4的超拟人1V1老师、销量破百万的墨水屏学练机(护眼+AI学练)及免费AI软件引关注,以教育AI融合推动个性化辅导与校园数字化,助力教育普惠新路径。

商汤「日日新V6.5」多模态大模型登顶OpenCompass全球榜单 超越Gemini 2.5 Pro与GPT-5
商汤「日日新V6.5」多模态大模型在OpenCompass评测中以82.2分超越Gemini 2.5 Pro与GPT-5,成全球领先。核心「图文交错思维链」技术贴近人类认知,优化视觉编码器与多模态网络,推理效率提升超三倍,标志中国AI在多模态通用智能领域迈入新阶段。
爱诗科技完成6000万美元B轮融资 刷新国内视频生成领域单次最大融资纪录 PixVerse V5图生视频全球第一
AI视频生成企业爱诗科技获阿里巴巴领投6000万美元B轮融资,系国内视频生成领域最大单次融资。公司以“让每个人成为生活的导演”为愿景,全球用户超1亿,自研PixVerse模型完成五次迭代,V5版本图生视频全球测评第一,开放平台半年生成视频超千万次,覆盖动态壁纸、公益等多元场景。
华为开源7B模型:快慢思考自适应 精度不减思维链缩短近50%
华为开源openPangu-Embedded-7B-v1.1大模型,创新“双重思维引擎”实现快慢思考自适应切换,采用渐进式微调训练。权威评测显示,通用任务(CMMLU)、数学难题(AIME)等精度提升超8%,思维链长度缩短近50%,效率精度双提升,同步推出1B边缘模型,开源推动行业创新。

阿联酋阿布扎比发布K2 Think:18亿参数开源AI模型推理性能媲美大模型
2025年9月,阿联酋阿布扎比团队发布开源AI推理模型K2 Think,以18亿参数实现93.5%推理准确率、32毫秒平均延迟,性能媲美35亿参数的GPT-X(94.2%)及28亿参数的DeepSeek Pro(93.8%),算力消耗降低40%,中小设备可高效部署。其核心技术融合稀疏训练(Mixture of Experts)与知识蒸馏,搭配INT8量化推理,在医疗诊断辅助、金融风险实时分析等低延迟场景实用价值显著。模型采用Apache 2.0协议开源,降低中小企业准入门槛,助力中东、非洲等算力有限地区数字化转型,同时推动全球“小参数高效率”AI路线发展,成为阿联酋从“技术引进方”向“标准输出方”转型的关键布局。
杜克大学陈怡然团队DPad方法:破解扩散大模型全局规划与效率两难,实现61倍加速
扩散大语言模型(dLLM)凭借全局规划能力在长文本生成等任务中表现突出,但因需对未来文本进行双向注意力计算,存在计算冗余、推理速度慢的痛点。杜克大学陈怡然团队提出的DPad方法,通过动态窗口聚焦近处关键“草稿纸”(后缀token)、先验丢弃远处冗余信息,实现效率与规划的平衡。该方案无需训练即可即插即用,在主流dLLM上实现61倍推理加速,精度损失不足0.5%,为实时长文本生成、边缘设备部署等场景扫清障碍,推动扩散模型工业化落地。
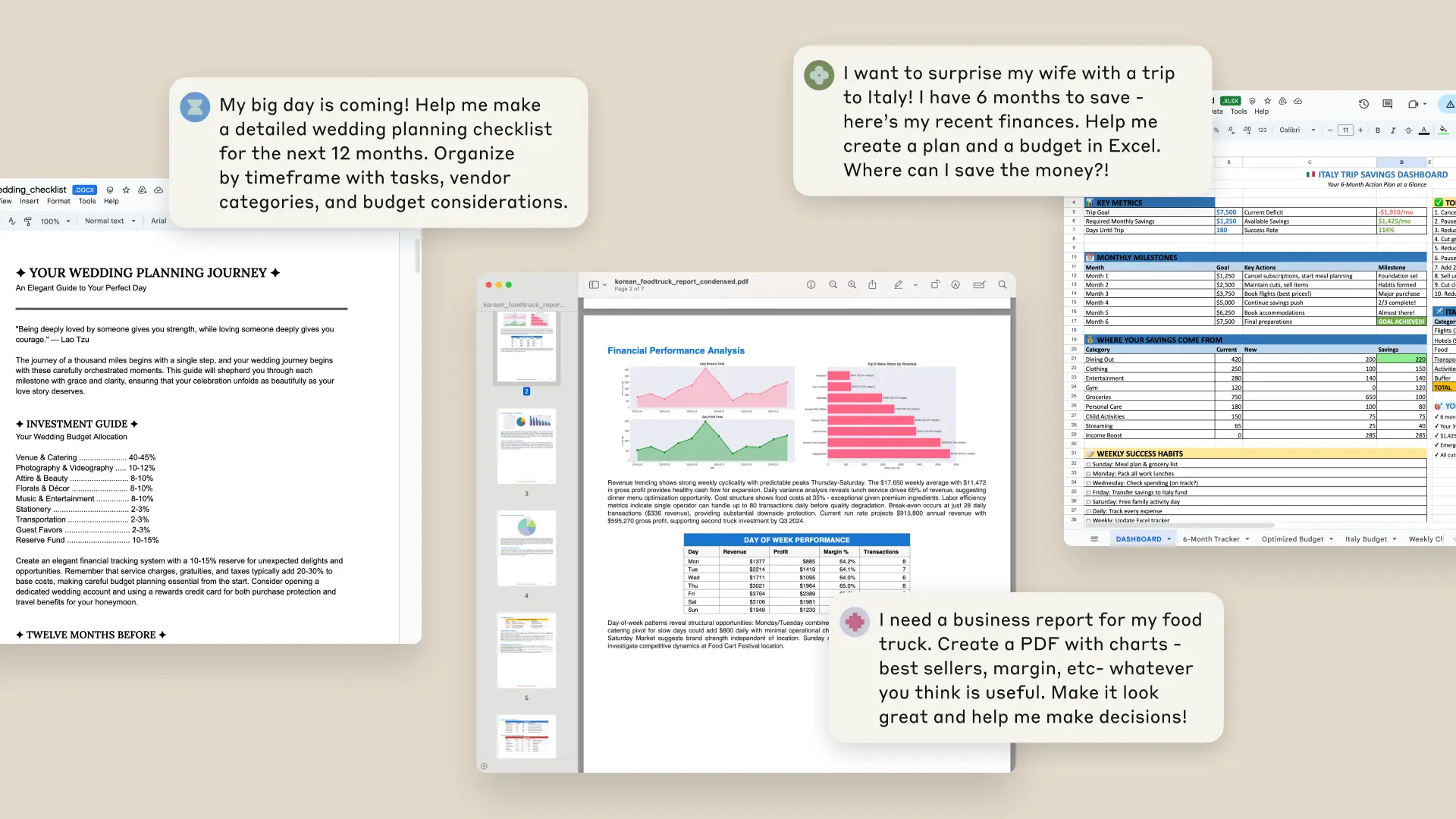
Anthropic Claude AI重大升级:可直接生成Excel/PPT/PDF办公文件
Claude AI迎来重大升级,新增服务器端隔离沙箱环境,支持直接生成和编辑Excel表格、PowerPoint演示文稿、PDF文档等20+格式办公文件,从智能顾问升级为主动协作者,大幅缩短需求到交付流程。通过独立Linux容器、完整工具链及原生文件引擎,实现“对话即生产力”——用户仅需自然语言描述需求,即可自动完成数据清洗、图表生成、格式排版,3分钟内交付可下载的成品文件,避免多工具切换。实测电商数据可视化、财务模型搭建等场景,可快速生成带动态公式的Excel或含趋势图表的PPT。相比ChatGPT等工具,其优势在于原生格式兼容、独立沙箱数据自动销毁保障安全,且直接输出成品文件。目前Max/Team/Enterprise版本已开放预览,Pro版即将上线,助力企业用户提升办公效率,实现人机协同新体验。
OpenAI技术双星Pachocki与Sidor:塑造AI巨头的关键路径
OpenAI CEO Sam Altman公开赞扬的“技术双星”Jakub Pachocki与Szymon Sidor,是OpenAI技术大厦的核心奠基者。二人分别主导算法突破与工程落地,从Dota 2项目验证强化学习规模化潜力,到GPT-4研发中实现参数量优化、推理效率跃升等关键突破,推动OpenAI技术边界扩张。2023年OpenAI“宫斗”事件中,他们联合技术团队以辞职施压,逆转董事会决策,彰显技术骨干话语权。而用户对ChatGPT标准语音退役、GPT-4o缩减服务的抗议,则折射出AI巨头在技术迭代与用户情感体验间的平衡挑战。这对“传奇搭档”的故事,既是AI技术狂飙突进的缩影,也为行业提供技术突破与用户需求协同的启示。
Unsloth框架:重新定义开源LLM微调的效率与稳定性标准
Unsloth作为新兴开源LLM微调框架,凭借内存优化技术与主流模型缺陷修复能力,重新定义本地化训练标准:在A100显卡上实现Llama-3 8B模型训练速度提升3.2倍、显存占用减少80%,且零精度损失。其通过OpenAI Triton内核重构计算模块,结合分层梯度检查点与4-bit量化技术,将Llama-3.1-8B微调显存需求从48GB降至12GB,使消费级RTX 4090也能胜任专业卡任务。团队深度参与开源生态,已修复Qwen3 128K上下文崩溃、Phi-3位置编码偏移等主流模型缺陷,相关补丁被llama.cpp、Microsoft等项目采纳。支持微调与RLHF一体化流程,广泛应用于法律科技(如LexNex合同分析)、电商客服(如ShopBot回复优化)等领域,经社区验证内存优化效果显著,有效降低中小团队AI个性化成本门槛。
Cognition融资4亿估值102亿,AI编程代理赛道迎里程碑
2024年AI编程代理赛道迎来里程碑,Cognition公司完成4.1亿美元融资,投后估值达102亿美元,由硅谷顶级风投Founders Fund领投,Lux、8VC等现有投资者及Bain Capital Ventures等新资本加持。其核心产品Devin作为“端到端自动化编程代理”,颠覆传统代码辅助工具,具备从需求到部署的全流程开发能力,代码生成准确率超90%,可替代20%-30%常规开发任务,实现从“辅助”到“独立代理”的跨越。本轮资金将用于Devin技术研发与全球扩张,推动AI编程进入“人机协作”新纪元,凸显资本市场对AI重构软件开发模式的高度认可。
Pollen Robotics开源"Amazing Hand"灵巧手:双手协同高精度,低成本驱动机器人灵巧操作革命
Pollen Robotics发布的开源“Amazing Hand”灵巧手双手机器人原型,凭借模块化设计与高精度控制实现技术突破:每手集成9关节6执行器,拇指支持对掌运动,可抓取0.5毫米至50毫米物体;磁性编码器提供0.1°关节反馈精度,能稳定操作0.8毫米间距芯片引脚。开源生态通过3D打印核心构件将单手套件成本压至200美元(仅为商用灵巧手1/20),GitHub开源设计文件、代码及ROS驱动吸引1700+星标开发者协作,已迭代触觉传感等功能。双手协同系统解锁工具切换、0.2毫米误差精密装配及动态抛接等复杂操作,在医疗微创手术、工业精密装配、核废料处理等场景落地测试。目前社区正优化肌腱耐久性(寿命提升至20小时),计划2025年推出商业套件,推动灵巧操作技术低成本普及。
蚂蚁集团AQ-MedAI提出DIVER框架:RAG技术从关键词匹配迈向逻辑链推理
传统RAG技术依赖关键词匹配,在医学诊断、数学证明等复杂任务中难以挖掘深度逻辑关联。为此,BRIGHT基准应运而生,聚焦推理密集型检索评价。蚂蚁集团提出DIVER框架,通过“预处理→查询扩展→推理检索→重排序”四阶段协同,将推理嵌入检索全流程,实现从关键词到逻辑链的跨越。该框架登顶BRIGHT基准,nDCG@10得分45.8,在医学、数学、编程等场景显著提升检索准确率,且泛化性强。目前论文、代码及模型已开源,助力AI从信息匹配迈向逻辑推理,赋能医疗辅助诊断、教育解题等领域发展。
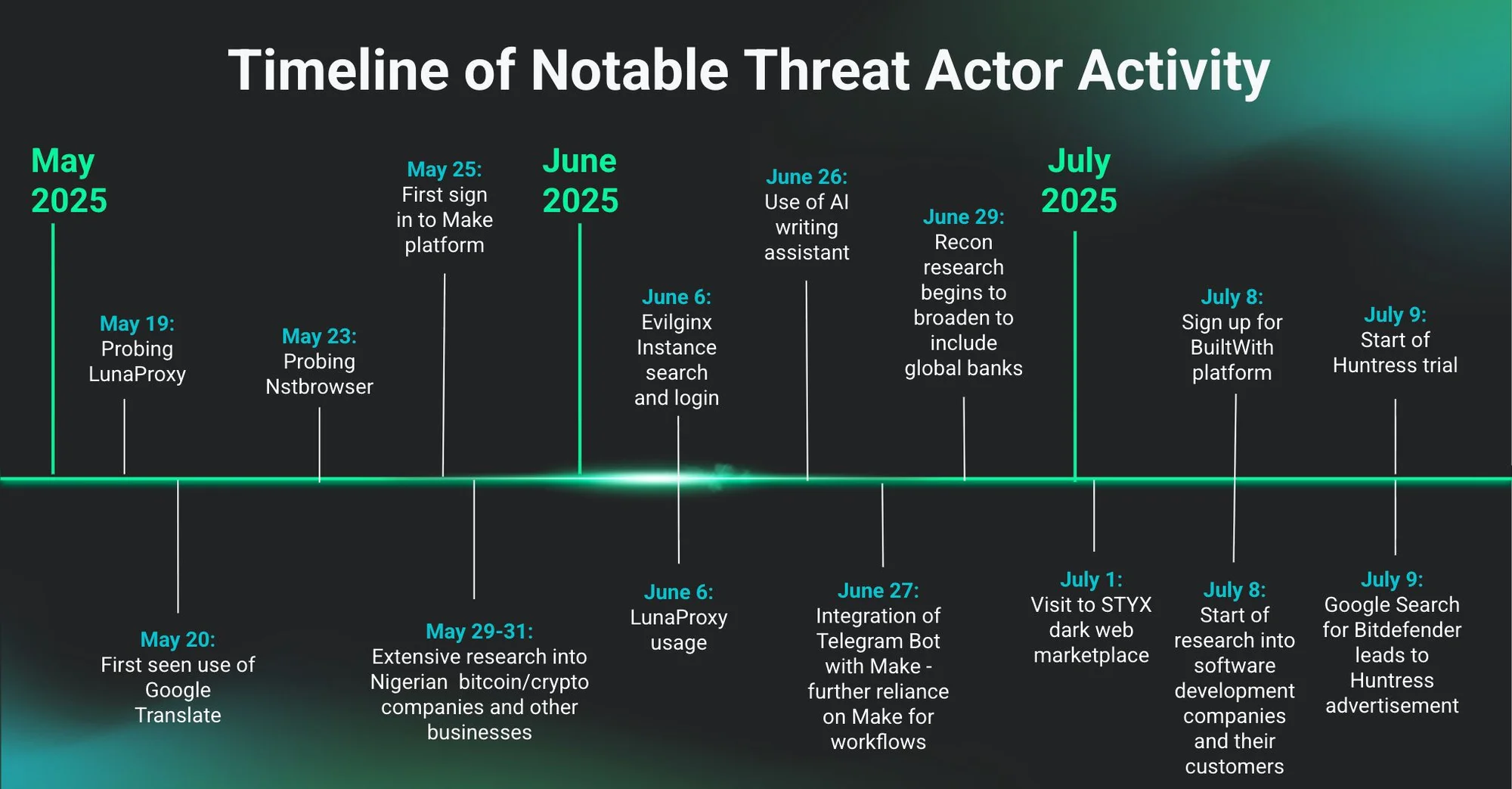
黑客误装Huntress代理自投罗网:AI驱动攻击全流程及VIRTUO基础设施揭秘
黑客误将Huntress安全代理安装在攻击主机,致其三个月操作被实时监控,首次完整暴露当代黑客AI驱动工作流。监控显示,攻击者利用AI工具链批量生成钓鱼邮件、自动关联漏洞,两周内操作2471+多行业独立身份,核心基础设施为涉62起APT事件的“防弹主机”AS 12651980(VIRTUO)。AI使攻击效率跃升,单日尝试从50次增至300次,成功率达28%,传统防御渐失效。企业需构建主动防御:监控非工作时段异常会话、用AI对抗AI、推动基础设施合规,以应对AI驱动的新型威胁。
百度文心大模型X1.1发布:三大核心能力跨越式提升,技术突破落地多场景
2025年WAVE SUMMIT大会上,百度发布文心大模型X1.1,实现事实性准确率提升34.8%、指令遵循优化12.5%、智能体能力增强9.6%,整体表现比肩GPT-5与Gemini 2.5 Pro。实测中,模型在逻辑推理(如"星球版农夫过河"问题)、事实检验(郑和下西洋伪史纠偏)、智能体多工具协同(小红书露营文案生成)等场景展现强落地能力。技术上采用混合强化学习与自蒸馏数据闭环,叠加思维链+行动链等三大模块强化推理与执行精度。同步升级的飞桨3.2框架,训练MFU达47%、推理2比特压缩降本增效,开源ERNIE-4.5-21B支持中小团队低成本开发。飞桨开发者超2333万,推动AI技术普惠与行业应用落地。
Perplexity推出政府专属AI服务:安全零门槛重塑公共治理效率
Perplexity推出美国政府专属AI服务“Perplexity for Government”,聚焦联邦、州、地方政府及教育组织,以“默认安全+零合同门槛”重塑政府AI接入模式。服务默认开启FedRAMP Moderate合规认证,数据全程美国境内AWS政府云处理,保障数据主权;零合同即开即用,50人以下小机构可免费使用基础功能,降低接入成本;支持GPT-4、Llama 3等多模型切换,适配政策分析、信息检索等多元场景。已应用于CDC疫情数据实时分析、EPA政策文件摘要生成等场景,响应白宫AI行政命令安全要求,推动政府AI从试点迈向规模化落地,为公共治理智能化提供高效、安全新方案。

腾讯云CodeBuddy三形态矩阵:插件+IDE+CLI重构AI编程全场景效率
腾讯云CodeBuddy AI编程工具矩阵正式发布,业内首创支持插件、独立IDE、CLI三形态,实现开发全场景无死角覆盖。其中CLI工具以“终端原生”设计,支持管道操作与脚本链集成,可通过自然语言驱动开发运维全流程,平均缩短40%任务处理时间;独立IDE同步开启公测,支持“对话即编程”,零代码生成全栈应用并直连腾讯云生态一键部署。三形态通过底层协同共享模型额度与开发环境,结合TEAC加密协议保障数据安全。相较竞品,CodeBuddy以全流程自动化能力与云生态深度整合,助力开发者与企业提升开发效率,推动AI编程从单一辅助向生产力平台进化。
MIT团队DSPy框架:以模块化编程重塑LLM应用开发流程
DSPy框架是MIT主导的开源LLM应用开发工具,以“签名式编程”为核心,通过结构化代码替代传统提示词工程,显著提升复杂AI任务开发效率。其“签名-模块-优化器”三位一体架构,支持任务接口标准化(签名定义输入输出)、LLM调用逻辑封装(内置ChainOfThought、ReAct等模块)及自动化性能优化(如BootstrapFewShot、GEPA等工具),解决了提示词碎片化、系统难维护等痛点。GEPA框架结合遗传算法与帕累托优化,实现多目标(准确率、延迟等)平衡,适用于客服智能体等复杂场景。实战案例Support-Sam客服智能体基于DSPy构建,以不足200行代码实现工单分类、知识库检索等全流程自动化。目前,Shopify、DeepLearning.AI等机构已将其用于生产环境,推动LLM应用开发从“作坊式调优”迈向工程化、模块化新阶段。
Interfaze LLM Alpha:模块化多模态架构成开发者工具链新选择
2025年9月推出的Interfaze LLM Alpha,是专为开发者打造的多模态AI工具链。其核心创新在于Router-Modules架构,通过“小模型专精+大模型统筹”模式,高效解决结构化数据提取、网页信息抓取、代码安全执行及OCR解析等开发痛点,冷启动延迟降低75%,内存占用节省70%。工具兼容OpenAI API协议,开发者可无缝迁移现有应用,无需重构代码。实测显示,其LinkedIn公司描述抓取准确率达92%,结构化数据提取F1值95.3,成本较GPT-4.1低57%,适合高频爬虫与批量处理场景。作为模块化架构代表,Interfaze推动AI模型从“参数竞赛”转向“架构优化”,为开发者提供高效、低成本的多模态开发解决方案。
甲骨文Q1财报:RPO激增359%股价暴涨27%,AI云服务驱动转型
甲骨文2026财年Q1财报发布后,股价盘后暴涨27%,核心驱动力为剩余履约义务(RPO)同比激增359%至4550亿美元,相当于过去25年营收总和。RPO中78%来自云服务合约(约3550亿美元),AI相关服务占比达64%,凸显转型成效。云基础设施(OCI)业务营收33亿美元,同比增长55%,增速持续提升,其与OpenAI合作集成GPT-5、与Google生态互补,满足企业AI算力需求,客户合同期限已延长至8年。此次RPO激增印证甲骨文从传统数据库厂商向AI云服务商转型,未来增长将深度绑定AI赛道。
Google AI Plus印尼首推 新兴市场低价定制启AI普惠
Google推出全新订阅服务“AI Plus”,聚焦新兴市场开启AI普惠化新尝试,首站落地印尼,后续将扩展至印度、泰国、墨西哥等地区。该服务针对新兴市场用户需求定制,印尼月费仅约4.56美元,不足美国同类服务价格的25%,锚定本地中端手机月分期费用降低付费门槛。核心功能涵盖Gemini 2.5 Pro(128K上下文窗口)、本地化AI工具集及Google Workspace深度集成,适配长文档分析、多轮对话等个人与中小微企业场景。免费版每日提供5次Gemini 2.5 Pro试用,引导用户转化。此举通过“低价+实用功能”组合,推动高端AI能力下沉,加速新兴市场数字经济效率提升,开启全球AI普惠化新阶段。