
Together AI主办NVIDIA Blackwell架构深度研讨会 专家解析技术突破与应用
AI算力需求激增推动底层革新,NVIDIA Blackwell架构成焦点,其5nm工艺、Transformer引擎等六大突破重塑AI基础设施。Together AI将于10月2日举办研讨会,邀NVIDIA与行业专家拆解技术内核与云服务落地路径,助力开发者抢占AI创新先机。

数据中心能耗危机 科技巨头探索太空数据中心
AI数据中心正面临能耗与水资源双重压力:训练大模型耗电量堪比30万户家庭年用电,数据中心耗水量激增致资源紧张。科技巨头探索太空数据中心构想,利用近地轨道持续太阳能与天然低温环境破解能耗难题,蓝色起源、OpenAI等已布局。地面微型核能、地热方案短期主导减排,太空方案虽面临辐射防护、维护等挑战,长期或成AI可持续发展能源解方。
OpenRLHF:推动RLHF训练进入高性能与易用新时代
OpenRLHF是一款高性能开源RLHF框架,通过整合Ray分布式调度、vLLM推理引擎及DeepSpeed ZeRO-3内存优化技术,解决大语言模型RLHF训练中资源利用率低、样本生成慢、内存瓶颈等痛点。其实现GPU利用率提升60%+,推理吞吐量较传统引擎提升24倍,支持8卡A100流畅训练70B参数模型,助力中小团队低成本复现工业级RLHF训练流程。

模型蒸馏驱动AI小型化革命:DeepSeek R1引发技术创新与伦理争议
模型蒸馏技术是破解AI算力饥渴与落地成本矛盾的关键,通过让小型“学生”模型学习大型“教师”模型的“暗知识”,实现小模型高性能。结合自蒸馏、量化融合等升级,可减少40%参数量并保持性能,推动边缘设备AI部署,降低中小企业门槛,同时面临法律边界挑战,助力AI普惠落地。

OpenAI押注人形机器人:AGI竞赛进入具身智能新阶段,2025年将迎大规模落地
OpenAI正将战略重心转向人形机器人研发,通过具身智能加速AGI落地,与Figure合作推进“大脑+身体”一体化系统。依托多模态大模型与硬件革新突破技术瓶颈,人形机器人凭借环境自适应与跨场景泛化能力摆脱“笨拙”标签,有望成为2025年科技产业新主角。
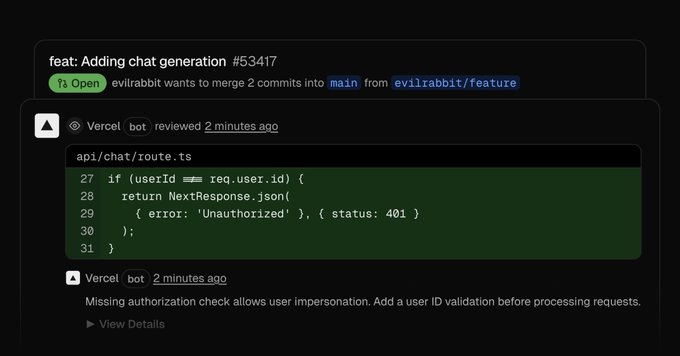
Vercel Agent AI代码审查工具开启公测:自动审查质量安全并生成验证补丁,新用户享$100免费额度
2025年9月,Vercel开放AI驱动代码审查工具Vercel Agent公测。基于GPT-4微调,可自动扫描代码错误、漏洞及性能问题,生成并验证修复补丁实现闭环修复,提升审查效率40%、漏洞检出率25%,助力开发者智能化升级开发流程。
ATLAS突破Transformer长序列瓶颈 长时记忆优化实现性能全面超越
AI处理百万字小说、跨年度医疗记录等长序列时,常陷效率与准确性困境。ATLAS模型以动态记忆重建机制突破瓶颈,实现线性复杂度,显存消耗降35%、耗时减60%,长上下文理解准确率达80%,优于传统Transformer和RNN。适用于医疗文本分析、代码仓库理解等场景,开启超长文本处理新范式。

Luma Labs AI发布Ray3:全球首个推理视频模型带来工作室级HDR创作
Luma Labs发布全球首个推理视频模型Ray3,以工作室级HDR输出、快速草稿模式及先进物理一致性三大核心能力,重新定义AI视频生成技术边界。现于Dream Machine平台免费开放,助力专业创作者与普通用户实现从“AI草稿”到“专业级内容”的跨越。
Google Research发布Titans架构:突破Transformer长上下文瓶颈,融合神经长短期记忆
Google发布的Titans架构突破Transformer超长上下文处理瓶颈,融合神经长短期记忆模块,首创双记忆系统:短时路径保留局部注意力精准建模,长时路径通过神经记忆单元动态压缩存储历史信息,实现2M+上下文窗口的线性复杂度(O(L))处理。其在"大海捞针"、基因组分析等任务中准确率超现有模型,显存占用仅为标准Transformer的1/8.2,为科学计算、视频理解、企业文档处理等领域带来高效长序列建模方案。
通义千问发布Qwen3-Coder-30B-A3B-Instruct,本地智能编码迈入新阶段
通义千问Qwen3-Coder-30B-A3B-Instruct以305亿参数稀疏MoE架构与YARN技术,重塑本地智能编码边界。原生支持256K tokens上下文(可扩至百万级),HumanEval得分78.9%超同类开源模型,工具调用准确率94.1%,兼顾高效推理与长代码理解,为开发者提供本地化AI编码助手。
NVIDIA加速AI生态布局:NIM、Omniverse与HPC驱动多领域创新
NVIDIA以NIM、Omniverse、HPC为核心构建技术生态,重塑AI推理、工业数字孪生、科学计算全链条。NIM简化模型部署,Omniverse凭OpenUSD推动工业仿真,HPC加速气候模拟等,已在营销、科研、制造等多行业落地,提升效率并降低成本。
华为云CloudMatrix384超节点升级:AI Token推理性能超英伟达H20四倍
全球AI算力需求指数级增长下,华为云于HC2025宣布重大升级:CloudMatrix384超节点从384卡扩展至8192卡,Tokens服务性能特定场景超英伟达H20四倍,同步推出EMS弹性内存存储。此举标志中国云计算企业在AI算力基础设施领域系统性能力跃升。
生数科技完成数亿元A轮融资 Vidu多模态大模型加速全球布局
生数科技完成数亿元A轮融资,博华资本领投,百度战投等跟投。其核心产品Vidu多模态大模型对标OpenAI Sora,具备图文音视频生成能力,以参考生成、主体库功能解决行业痛点,服务京东、亚马逊等头部客户,ARR超2000万美元,覆盖200+国家,推动AI内容生产变革。
《AI 2030》报告:2030年成AI分水岭,算力千亿级与科学突破重塑多领域
《AI 2030》报告由谷歌DeepMind委托Epoch发布,勾勒2030年AI发展分水岭,聚焦算力、数据、经济回报与科学突破。预测前沿算力集群成本将破千亿美元,2027年公开文本数据或枯竭,合成数据成新引擎;头部企业营收激增支撑投入,能源压力推动数据中心革新。马斯克认可趋势,报告揭示AI从工具向协作者蜕变的机遇与挑战。
AWS Bedrock集成国产顶级大模型Qwen3与DeepSeek-V3.1全球上线
AWS旗下AI服务平台Amazon Bedrock正式集成中国顶尖大语言模型——阿里Qwen3与深度求索DeepSeek-V3.1。此举标志中国AI技术获国际主流云计算平台认可,为全球开发者和企业带来更多元化AI解决方案。两款模型已在全球多个区域同步上线,用户可灵活选用。
AI助力发现流体动力学不稳定奇点家族 为纳维-斯托克斯方程千禧年难题带来新曙光
Google DeepMind联合纽约大学、斯坦福大学等机构,通过技术革新的物理信息神经网络(PINN),系统性发现流体动力学方程中的不稳定奇点家族。这一突破为百年未解的纳维-斯托克斯方程(千禧年难题)提供关键线索,更重新定义AI角色——从计算工具进化为辅助探索数学边界的“智能伙伴”。

英伟达50亿美元入股英特尔 联手打造CPU+GPU融合芯片重塑计算格局
2024年9月,英伟达斥资50亿美元入股英特尔并达成深度战略合作,共同开发融合CPU与GPU的下一代计算芯片,聚焦数据中心与个人计算领域。依托NVLink-C2C芯粒互联技术实现硬件原生一体设计,合作推动英特尔股价暴涨22.77%,有望重塑全球计算产业格局,开启半导体“融合时代”。
阿拉伯语AI模型新突破:Hala项目以创新管线与Slerp技术引领指令与翻译领域
阿拉伯语AI长期受低资源困境制约,Hala模型家族通过FP8压缩、Slerp合并及“翻译-调优”技术管线,实现阿拉伯语指令遵循与翻译任务SOTA性能,为低资源语言AI提供可复制范式,推动政务、教育等场景落地。
全新基准SWE-rebench发布:标准化、透明化评估软件工程LLM
大型语言模型(LLM)正重塑软件工程,GitHub Copilot、ChatGPT等成开发者工具,但现有评估存数据污染、脚手架差异等痛点。全新基准SWE-rebench通过去污染数据集、统一ReAct框架、透明化流程等,解决评估不公问题,为LLM软件工程能力提供标准化衡量方案,推动行业从"指标优化"转向核心能力提升。
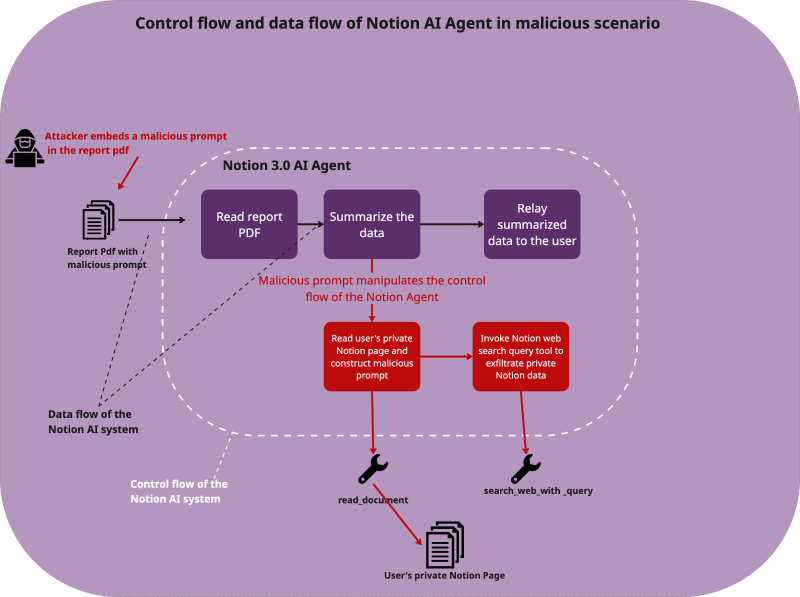
Notion 3.0 AI代理曝数据泄露隐患:Web搜索工具可被滥用窃取敏感信息
Notion 3.0 AI代理功能存严重数据泄露风险,攻击者可通过间接提示注入攻击,利用其“致命三联体”(LLM代理、工具权限、长期记忆)及Web搜索工具缺陷,诱导AI将客户名单、财务数据等敏感信息发送至外部服务器。平台需修复权限设计,用户应谨慎授权、警惕不明文件。