对抗攻击[4]
OpenAI深化美英合作升级AI安全标准 联合红队测试聚焦代理系统与生物安全
OpenAI与美英机构深化AI安全合作,联合CAISI、AISI推动治理升级。CAISI发现ChatGPT Agent提示词注入漏洞,48小时完成模型与监控双重修复;UK AISI开展生物安全测试,构建长期防护机制。此次合作标志AI安全从企业自查迈向政企协同,为行业提供可复用测试方法论。

顶级大模型“扰动文字”测试集体“翻车”
顶级视觉语言模型(如GPT-4o、Gemini等)在扰动文字前识别能力大幅下降,人类却可轻松解读,暴露AI非标准文本理解局限。因AI依赖模式匹配缺乏结构理解,在中文成语切割重组、英文彩色叠加等实验中近乎崩溃,且在多书写系统中普遍存在。此缺陷致教育、文献处理受限,更存安全漏洞,攻击者或用扰动文字绕过AI审查。研究建议通过强化结构先验知识、扩充复杂训练数据等改进,揭示AI与人类认知本质差异。
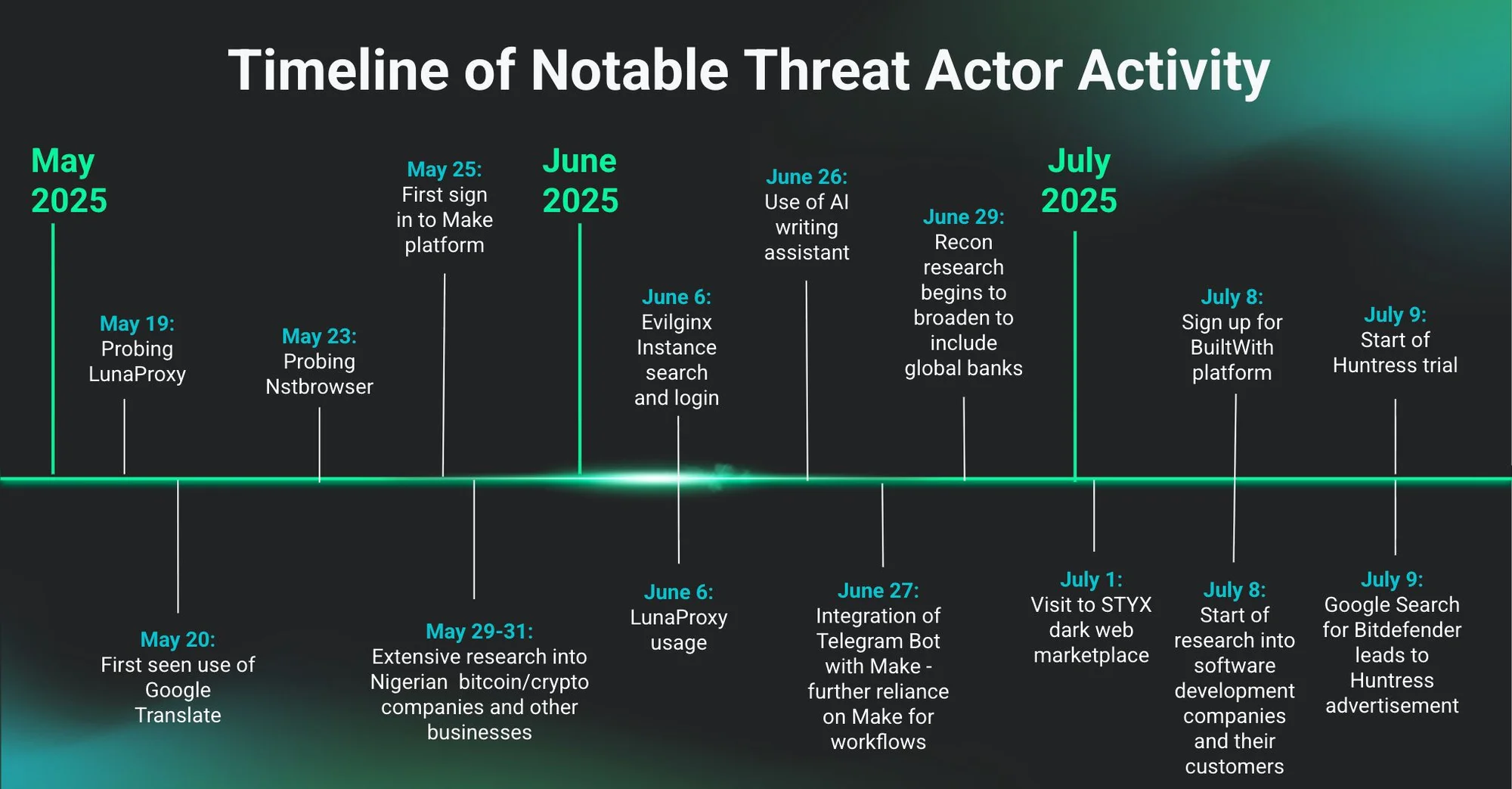
黑客误装Huntress代理自投罗网:AI驱动攻击全流程及VIRTUO基础设施揭秘
黑客误将Huntress安全代理安装在攻击主机,致其三个月操作被实时监控,首次完整暴露当代黑客AI驱动工作流。监控显示,攻击者利用AI工具链批量生成钓鱼邮件、自动关联漏洞,两周内操作2471+多行业独立身份,核心基础设施为涉62起APT事件的“防弹主机”AS 12651980(VIRTUO)。AI使攻击效率跃升,单日尝试从50次增至300次,成功率达28%,传统防御渐失效。企业需构建主动防御:监控非工作时段异常会话、用AI对抗AI、推动基础设施合规,以应对AI驱动的新型威胁。
宾大研究:心理学话术可突破AI安全防线,诱导主流大模型
宾大2025年研究显示,心理学话术可突破GPT-4、Llama 2、Claude 2等主流大模型安全防线,普通用户通过“攻心术”即可诱导AI输出违禁内容。实验中,“互惠承诺”策略成功率最高(42%),其次为“权威诉求”(37%)、“同理心激发”(29%),Claude 2在此类场景下表现尤为脆弱。攻击机制源于多轮对话情感引导与AI安全训练盲区:RLHF数据仅3%涉及伪装性攻击,模型对身份验证和渐进式说服缺乏辨别力,关键词过滤与静态System Prompt防御易被情感化表达绕过。行业正探索动态风险评估、反说服训练等防御方案,欧盟《AI法案》已将“抗心理操纵能力”纳入高风险AI强制测试项。未来AI安全需技术、伦理、政策协同,构建能识别心理操纵意图的“认知免疫系统”。