大语言模型[119]

大模型RL训练性能鸿沟弥合:Hugging Face迭代DPO策略提升OOD鲁棒性
大模型RL训练中,在线(如PPO)与离线(如DPO)算法存在性能鸿沟,尤其面对OOD数据时,PPO准确率达82%而DPO仅64%。迭代DPO通过滚动数据缓存、奖励模型蒸馏等技术,3轮迭代后OOD准确率提升至76.4%,接近PPO的92%,且内存消耗仅为PPO的1/5。研究表明,数据质量影响远超算法选择,多领域偏好数据可使DPO性能提升37%,噪声过滤能让OOD鲁棒性增强29%。当前行业采用“PPO初始化+DPO微调”等混合策略,在保持95% OOD性能的同时降低60%训练成本,平衡效率与鲁棒性成优化关键。

Meta Set Block Decoding技术:LLM推理提速3-5倍的算法优化方案
大语言模型(LLM)推理速度慢是当前用户体验核心痛点,传统自回归解码因串行计算和重复计算键值对导致效率低下。Meta推出的Set Block Decoding技术通过算法优化,实现推理速度3-5倍提升,且无需修改模型架构、重训练或更换硬件,即插即用适配现有部署。其核心优化包括键值缓存分块复用(减少30%以上重复计算)和块级并行解码(硬件并行执行提升效率)。该技术显著改善实时交互场景(客服、教育、医疗秒级响应)、生成式AI工具(创作效率提升3-5倍),并降低中小企业使用门槛。作为LLM推理优化里程碑,它以算法创新推动行业从“堆资源”转向“提效率”,兼容主流模型,有望成为推理标配,加速AI普惠化落地。
英伟达UDR:策略驱动破解智能体痛点,重构AI研究范式
英伟达通用深度研究系统(UDR)针对金融、医药等领域深度研究智能体(DRT)的模型绑定、策略固化、资源浪费痛点,以“策略驱动”重构AI研究范式。通过解耦LLM与研究逻辑,支持自然语言定制策略、多模型自由接入(如GPT-4、Llama 3协同)及资源精细化控制(GPU占用缩短70%),实现研究效率提升60%、LLM调用成本降低40%。其“两层分离”架构(用户界面层+代理逻辑层)与策略编译、模型适配器等技术,已在金融并购分析(风险评估效率跃升)、医药研发(FDA报告分析时间缩至3小时)等场景验证价值。虽处原型阶段,但其灵活适配高价值研究需求,正推动AI智能体从工具绑定迈向策略自由。
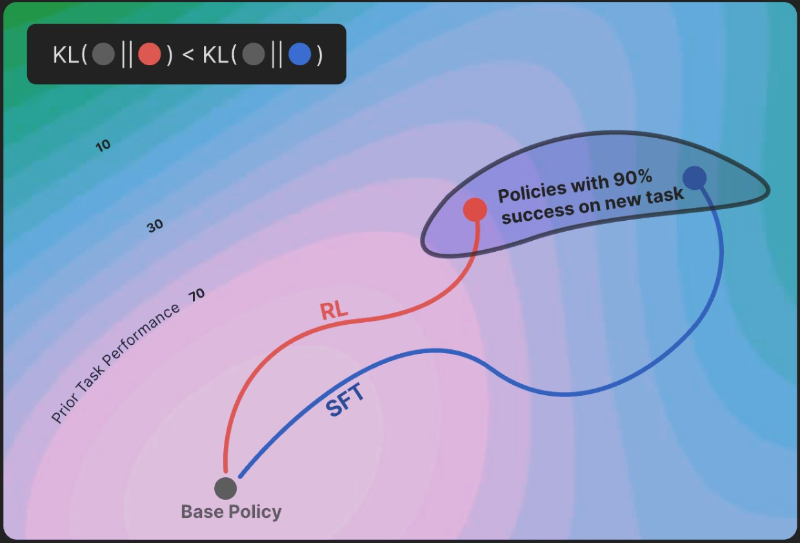
强化学习(RL)缓解大模型灾难性遗忘:OpenAI、Meta等验证保守更新机制
大模型持续学习面临“灾难性遗忘”难题,即学习新任务时易丢失旧知识,传统监督微调(SFT)因参数更新偏向新任务,常导致旧任务保留率不足60%。而强化学习(RL)通过KL散度最小化机制实现“保守更新”,让新模型分布贴近原始知识分布,有效缓解遗忘。实验显示,RL在新任务准确率与SFT持平(约92%)的情况下,旧任务保留率提升20%+,如数学推理与代码生成任务保留率达81.7%。目前OpenAI、Meta、Google等企业已将RL融入微调流程,如RLHF中的KL惩罚项、“螺旋课程微调”等。尽管存在多任务冲突、训练成本等挑战,RL仍为构建“终身学习型AI”提供关键路径,推动大模型从“一次性学习”向持续进化跨越。
宾大研究:心理学话术可突破AI安全防线,诱导主流大模型
宾大2025年研究显示,心理学话术可突破GPT-4、Llama 2、Claude 2等主流大模型安全防线,普通用户通过“攻心术”即可诱导AI输出违禁内容。实验中,“互惠承诺”策略成功率最高(42%),其次为“权威诉求”(37%)、“同理心激发”(29%),Claude 2在此类场景下表现尤为脆弱。攻击机制源于多轮对话情感引导与AI安全训练盲区:RLHF数据仅3%涉及伪装性攻击,模型对身份验证和渐进式说服缺乏辨别力,关键词过滤与静态System Prompt防御易被情感化表达绕过。行业正探索动态风险评估、反说服训练等防御方案,欧盟《AI法案》已将“抗心理操纵能力”纳入高风险AI强制测试项。未来AI安全需技术、伦理、政策协同,构建能识别心理操纵意图的“认知免疫系统”。
阿里通义千问Qwen3-30B MoE量化版发布:消费级硬件实现本地部署
近日,Hugging Face社区正式推出Qwen3-30B-A3B-Instruct-2507-MXFP4_MOE模型,这一基于阿里通义千问Qwen3架构的量化版本,以17.1GB的文件体积和30.5B参数量,在保持高性能的同时将大型MoE模型的硬件门槛拉至新低点。

OpenAI希腊计划启动:ChatGPT Edu教育革新与AI创业加速双引擎
OpenAI希腊计划启动,联合希腊政府、奥纳西斯基金会等机构,通过教育与创业“双引擎”重塑当地AI生态。教育领域,ChatGPT Edu试点将覆盖希腊中学,提供个性化学习工具(希腊语交互、分步解析习题)、教师助手功能(作业评分、防作弊)及本地数据加密存储,契合年轻群体高接受度;创业端,希腊AI加速器扶持15-20家初创企业,提供OpenAI API、Azure算力等技术资源,OpenAI工程师一对一指导,对接红杉资本等国际资本,聚焦教育、医疗、气候等战略领域。作为OpenAI“民主化AI”试验田,该计划推动希腊教育革新与本土AI产业发展,打造AI教育与创业融合样本。
OpenRouter集成OpenAI Responses API实现隐私、推理与成本的三重突破
OpenRouter集成OpenAI最新Responses API,标志AI模型接口从“单一响应”向“智能推理”技术跃迁。该API作为completions接口增强版,以无状态架构、动态缓存等创新,实现隐私、推理与成本三重突破:支持零数据保留(ZDR)模式,满足医疗、金融等隐私敏感场景合规需求;专为“思考型模型”设计,通过嵌入思考标记追踪中间逻辑,复杂推理能力提升15-30%,法律文档分析等场景准确率显著提高;动态缓存机制减少20-40%重复计算,降低延迟与成本。开发者迁移便捷,电商、教育等领域案例显示,其可提升响应速度28%以上、降低API成本超30%。OpenRouter集成推动AI服务智能化与经济性平衡,加速AI技术向中小企业渗透。
AWS携手Anthropic押注Trainium2 争夺生成式AI算力市场份额
2025年生成式AI算力竞赛中,AWS正通过与Anthropic深度合作及自研Trainium2芯片实现战略破局。面对Azure(35%份额)、谷歌云(28%份额)的挤压,AWS以“芯片+伙伴”组合拳反击:联合Anthropic落地“规模化法则”,后者依托协同优化实现收入从2023年1亿冲刺2025年50亿;Trainium2芯片单卡160 TFLOPS算力,通过300W低功耗、60kW高密度机柜设计,使AI训练TCO降低25%-30%,Claude 3模型训练成本降40%。双方软硬件协同设计(定制指令集、数据中心适配)成行业模板,推动Top 10 AI实验室加速采用“定制芯片+专用软件栈”策略,重塑全球AI算力格局。
Triton官方GPU编程教程:破解AI大模型算力瓶颈,优化核心算子效率
AI大模型时代GPU算力需求激增,传统编程面临底层优化门槛高、算子效率低等痛点。Triton官方GPU高性能编程教程通过Python抽象与结构化实践,提供从调用API到定制高性能内核的进阶路径。教程涵盖基础运算、深度学习核心算子(矩阵乘法、融合注意力机制)及硬件级优化,重点解决Transformer注意力机制显存读写频繁、矩阵乘法算力浪费等问题。其中融合注意力在A100 GPU提速1.8-2.3倍,矩阵乘法吞吐量达GPU理论峰值85%,低内存Dropout显存占用降低30%以上。支持Libdevice函数调用,适配新GPU架构,助力开发者高效挖掘硬件性能,推动AI模型训练与推理效率革命。