AI安全[2]
Meta开源LlamaFirewall:LLM安全防护工具免费开放,防御越狱、目标劫持等威胁
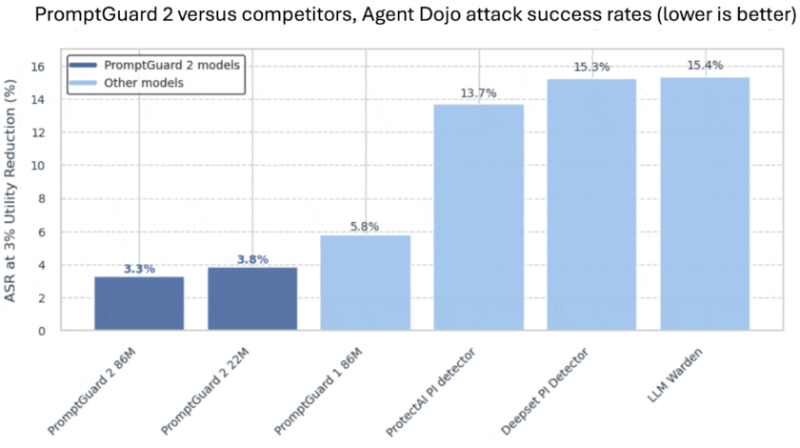
Meta开源LlamaFirewall,为LLM筑起免费安全防线。针对越狱攻击、目标劫持、代码漏洞三大威胁,采用输入/推理/输出分层防御架构,实时拦截攻击提示词、审计推理过程、扫描代码漏洞。7亿MAU以下项目免费使用,助力开发者零成本保障AI安全。

顶级大模型“扰动文字”测试集体“翻车”
顶级视觉语言模型(如GPT-4o、Gemini等)在扰动文字前识别能力大幅下降,人类却可轻松解读,暴露AI非标准文本理解局限。因AI依赖模式匹配缺乏结构理解,在中文成语切割重组、英文彩色叠加等实验中近乎崩溃,且在多书写系统中普遍存在。此缺陷致教育、文献处理受限,更存安全漏洞,攻击者或用扰动文字绕过AI审查。研究建议通过强化结构先验知识、扩充复杂训练数据等改进,揭示AI与人类认知本质差异。